F. Barthélemy
Soit le programme JAVA suivant:
class A{
void m(A a){
System.out.println("m de A");
}
void n(A a){
System.out.println("n de A");
}
}
class B extends A{
void m(A a){
System.out.println("m de B");
}
void n(B b){
System.out.println("n de B");
}
public static void main(String[] argv){
A a = new B();
B b = new B();
a.m(b);
a.n(b);
}
}
Question: deviner ce qu'affichera l'exécution de la méthode main de B.
Réponse:
m de B n de A
En fait, presque toutes les combinaisons possibles auraient été logiquement concevables. Pour savoir à l'avance, quand on écrit ce programme, ce qui va se produire, il faut connaître la sémantique opérationnelle de JAVA qui elle-même ne peut se décrire qu'en fonction du typage. Connaître les règles de typage employées est donc indispensable pour comprendre certains phénomènes étranges qui peuvent arriver.
On reprendra le petit jeu un peu plus loin avec d'autres exemples tout aussi surprenants.
En JAVA, les types sont déclarés par l'utilisateur. Chaque variable, chaque méthode a un certain type.
Les types utilisés dans les déclarations et les conversions explicites:
En plus de ces types que l'utilisateur est amené à taper dans ses programmes, il est utile pour expliquer le typage de considérer le type d'une méthode comme un type fonctionnel (analogue à celui des fonctions Ocaml). Une méthode:
t0 m(t1 a1,..., tn an){ ... }
a le type t1
La relation de sous-typage est défini de la façon suivante en JAVA:
En plus de ces règles, on ajoute quelques règles ayant un but technique. Considérer qu'un type est son propre sous-type permet de simplifier le typage. D'autre part, la valeur null est utilisée pour représenter la valeur indéfinie dans toutes les types référence (classes et tableaux). Il faut pouvoir typer cette valeur. Pour ce la on crée le type nil qui n'aura que cette valeur et nil est un sous-type des types références.
En JAVA, on peut parfaitement utiliser dans une déclaration un type qui est défini plus loin dans le même fichier source.
Par exemple:
class A extends B{
...
}
class B{
...
}
Cela permet entre autres de définir facilement des classes mutuellement récursives:
class A{
B b;
...
}
class B{
A a;
...
}
à comparer avec par exemple ADA:
type B; -- declaration type A is -- declaration et definition ... type B is -- definition ...
Pour pouvoir typer A, il faut néanmoins déjà connaître B pour savoir par exemple que B existe (sinon, A est mal typé, et quels messages sont susceptibles d'être envoyés à la variable b.
Cela signifie qu'avant de pouvoir vérifier que A est correctement typé, il faut avoir déjà parcouru tout le fichier pour recueillir les déclarations de type. Ce passage préalable sert à construire l'environnement de typage.
Il contient l'information donnée par toutes les déclarations de types du fichier analysé. Cette information est structurée autour des classes et des interfaces.
L'information associée à un nom de classe dans l'environnement de typage comprend:
L'information donnée sur une interface est:
Le premier passage permet de construire un environnement de typage utilisé lors du second passage pour vérifier que le programme est correctement typé. Au cours de cette vérification, on peut être amené à ajouter dans l'environnement de typage le type de variables locales ou de paramètres de méthodes. Cela apparaîtra clairement dans certaines règles de typage.
Une classe C est correctement typée si les contraintes suivantes sont respectées:
T m(T1 x1,...,Tn xn){
inst1;
...
instm;
return exp;
}
La méthode m est bien typée dans un contexte de typage A si la contrainte suivante est respectée:
Pour typer v = e dans un contexte de typage A:
Ce qui peut sécrire avec la règle:
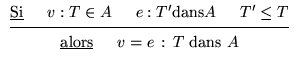
Le type donné à l'instruction toute entière est void. Ce n'est pas le type obtenu qui nous intéresse ici, mais le fait que ce type n'est obtenu que si l'instruction est correctement typée.
Une variable d'instance est déclarée de la façon suivante:
T v = e;
Elle est correctement typée dans un contexte A si e a dans un A un sous-type T' de T.
Pour vérifier toutes les déclarations de variables d'instance d'une classe, il faut rajouter au fur et à mesure les variables d'instances dans l'environnement de typage.
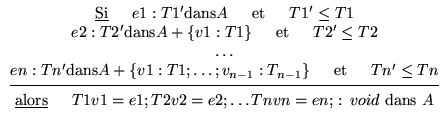
Exemple:
class A{
int i = 3;
int j = i;
...
}
Nous avons déjà vu le typage de l'affectation. Nous n'allons pas détailler le typage de toutes les instructions et des expressions, qui est très classique. Nous allons nous concentrer sur ce qui est le plus intéressant.
Pour typer une séquence d'instructions, il faut typer chaque instruction en augmentant le contexte de typage avec les variables locales. Les instructions ont pour type void sauf return exp qui a le type de exp. Une séquence a le même type que la dernière instruction.
Conversions explicites de types:
(T) expest bien typé dans A si exp:T'
Ceci n'est qu'approximativement vrai. Voir ci-dessous le complément sur le typage dynamique.
New:
new T() est bien typé si ![]() est une classe dans le contexte
de typage, et le type de
est une classe dans le contexte
de typage, et le type de new T() est T.
On est là au c![]() ur du langage et de la difficulté.
ur du langage et de la difficulté.
JAVA admet la surcharge de méthodes: une classe peut contenir plusieurs méthodes de même nom à condition que les types des paramètres soient différents. Il faut choisir la méthode qu'on va appliquer au seul vu des types des paramètres effectifs présents à l'appel.
Cela concerne plutôt la sémantique d'exécution que le typage. Mais en fait, on a aussi besoin de connaître la méthode qui sera choisie pour typer: en effet, il faut connaître le type de la valeur de retour de la méthode.
Par exemple, si l'objet o a les deux méthodes m,
l'une de type T1 ![]() int et l'autre de type T2
int et l'autre de type T2
![]() bool, la déclaration:
bool, la déclaration:
int i = o.m(l);peut être bien ou mal typée, selon la méthode effectivement sélectionnée.
Il faut donc assurer que le même choix sera fait par l'algorithme de typage et par le compilateur (éventuellement le choix peut être retardé jusqu'à l'exécution).
Supposons que l'on doive typer dans un environnement A l'envoi de message:
exp.m(exp1,...,expn)et qu'une seule méthode m existe.
On va utiliser dans la règle qui suit une opération qui recherche la méthode m de la classe T dans A, notée rec(m,T,A). Nous décrirons plus loin cette recherche.

La résolution de la surcharge, autrement dit le choix d'une méthode parmi toutes celles qui ont le même nom, s'effectue sur la base des informations de typage.
D'une part, les paramètres effectifs de l'envoi de message sont typés. Cela donne une approximation du type de la méthode qui sera utilisée. En fait, ça donne un sous-type des arguments.
Le contexte de typage donne, entre autres, pour chaque classe, le nom de la super-classe et le type de toutes les méthodes définies dans la classe. Quand on cherche une méthode, on va d'abord regarder dans la classe, puis dans la super-classe et dans la super-classe de la super-classe, jusqu'à la racine de l'arborescence.
Au cours de cette recherche, on ne va pas s'arrêter à la première méthode ayant le bon nom et un type compatible avec les paramètres effectifs: on recueille l'ensemble des méthodes possibles, et on choisit dans cet ensemble.
L'ensemble des méthodes qui conviennent (nom et super-type des arguments) est ordonné selon deux critères: le type des arguments et la classe où la méthode est définie.
![]()
Cet ordre est utilisé pour sélectionner la plus petite méthode de l'ensemble.
Exemple:
class A{
int m(A a){
return 1;
}
}
class B extends A{
bool m(B b){
return true;
}
}
Typons (new B()).m(new B()). Dans le contexte courant, |
new B(): B| et new B(): B. On va donc rechercher dans B les
méthodes m ayant un seul paramètre qui est d'un super-type de B.
On obtient deux méthodes:
m de B qui a un paramètre de type B (notons-là (B, B))
m de A qui a un paramètre de type A (A,A).
On a ![]() et
et ![]() , d'où on déduit
, d'où on déduit
![]() .
La méthode de B est la plus petite, c'est elle qui est choisie et le
type de
.
La méthode de B est la plus petite, c'est elle qui est choisie et le
type de (new B()).m(new B()) est bool.
Il peut arriver que deux méthodes ne soient pas comparable selon l'ordre défini entre les méthodes (il s'agit d'un ordre partiel).
Exemple:
class A{
int m(B b){
return 1;
}
}
class B extends A{
bool m(A a){
return true;
}
public static void main(String[] argv){
(new B()).m(new B());
}
}
Il faut comparer ![]() avec
avec ![]() : il n'y en a pas un plus petit
que l'autre. Dans ce cas l'ordre ne permet pas de choisir, l'envoi de
message est mal typé.
: il n'y en a pas un plus petit
que l'autre. Dans ce cas l'ordre ne permet pas de choisir, l'envoi de
message est mal typé.
$ javac B.java
B.java:12: Reference to m is ambiguous. It is defined in boolean m(A)
and int m(B).
(new B()).m(new B());
^
1 error
Tout ça est assez compliqué. Dans la pratique, on aura intérêt à ne pas abuser de la surcharge.
Le masquage de méthode est une clé de la liaison retardée. C'est quelque chose d'important.
Les règles de typage nous montrent qu'une méthode ne peut en cacher une autre que si elle a exactement le même type.
Si deux méthodes de même nom ont le même type, alors quel que soit le contexte de typage, au plus l'une des deux peut être utilisée.
Si deux méthodes de même nom n'ont pas le même type, alors l'une ne peut pas masquer l'autre dans tous les cas d'envoi de message.
class A{
boolean m(A a){
return true;
}
}
class B extends A{
boolean m(A a){
return false;
}
public static void main(String[] argv){
A a;
a = new B();
a.m(a);
}
}
Remarquons d'abord que l'ordre sur les méthodes est tel que
![]() . Cela signifie que si on a accès aux deux
méthodes, ce sera toujours la même qui sera choisie (celle de B).
. Cela signifie que si on a accès aux deux
méthodes, ce sera toujours la même qui sera choisie (celle de B).
Voyons ensuite comment est typé le corps de la méthode main
dans un contexte de typage ![]() ={A: (super-classe: Object,
meth: (m: A
={A: (super-classe: Object,
meth: (m: A
![]() boolean)), B: (super-classe: A, meth: (m: A
boolean)), B: (super-classe: A, meth: (m: A
![]() boolean))}. C'est à dire, dans un contexte où les
deux classes A et B sont connues.
boolean))}. C'est à dire, dans un contexte où les
deux classes A et B sont connues.
La déclaration A a; fait qu'on ajoute a:A à
![]() .
.
![]() .
On type l'affectation
.
On type l'affectation a = new B(); dans ![]() . Sans
problème (cf règle de l'affectation).
. Sans
problème (cf règle de l'affectation).
On en arrive à l'envoi de message a.m(a) qu'il faut typer
dans ![]() .
D'abord il faut typer a. Le type est donné à a par le
contexte de
typage
.
D'abord il faut typer a. Le type est donné à a par le
contexte de
typage ![]() est A.
est A.
On cherche ensuite dans ![]() les méthodes m de A. Il n'y en a
qu'une, (A,A). On utilise le type de cette dernière pour typer
le résultat: boolean.
les méthodes m de A. Il n'y en a
qu'une, (A,A). On utilise le type de cette dernière pour typer
le résultat: boolean.
Or à l'éxécution, du fait de la liaison tardive, c'est l'autre méthode, celle de B qui est exécutée. Autrement dit, on se trouve dans une situation paradoxale qui fait qu'on utilise une méthode au typage et une autre à l'exécution. Notons qu'on ne peut pas toujours savoir au typage quelle sera vraiment la méthode exécutée. Elle peut d'ailleurs ne pas encore exister au moment où on compile le programme.
Mais du fait que les deux méthodes ont exactement le même type, on est sûr de ne pas introduire d'erreur de type en utilisant l'une à la place de l'autre.
Le typage statique détermine le type de la méthode. Ce type est fixé à la compilation et inscrit en dur dans le code compilé. On ne revient jamais sur un type.
La méthode effectivement appliquée est recherchée dynamiquement, à l'exécution dans la classe de l'objet. Il s'agit ici non du type donné à l'objet par sa déclaration (ou type déclaré) mais du type effectif de l'objet, ou type constaté.
Par exemple:
A a = new B();a a pour type déclaré A et pour type constaté B.
Parfois, le type constaté ne peut pas être déterminé:
if (maClasse.booleenAleatoire()){
a = new A();
}
else{
a = new B();
}
On ne peut constater le type de a qu'après que la condition a été évaluée.
La recherche de la méthode se fait en remontant dans l'arbre d'héritage depuis le type constaté. Cette recherche est nécessairement fructueuse: on est sûr qu'il existe au moins la méthode qui a servi au typage. Eventuellement, on en trouvera une autre avant, située en-dessous et qui la masque.
Le typage assure donc que l'objet possède la méthode.
On a deux phénomènes distincts, qui ne sont pas très compliqués chacun mais qu'il n'est pas évident de distinguer au premier abord.
D'un côté il y a la surcharge: le même nom est donné à des méthodes conceptuellement différentes. Il y a une règle simple (ordre entre les méthodes) pour choisir entre plusieurs méthodes dont le type convient pour un envoi de message donné. Mais cette règle ne marche pas dans tous les cas de figure envisageables (cf exemple d'ambiguïté.
D'autre part il y a le masquage, qui consiste à remplacer une méthode par une autre, dans un contexte déterminé. Cela n'est possible qu'en cas d'égalité stricte des types. C'est le masquage qui est à la base de la liaison tardive.
class A{
void m(A a){
System.out.println("m de A");
}
void applyM(A a){
a.m(a);
}
}
class B extends A{
void m(B b){
System.out.println("m de B");
}
public static void main(String[] argv){
B b = new B();
b.m(b);
(new A()).applyM(b);
}
}
$ javac B.java
$ java B
m de B
m de A
JAVA n'est pas entièrement typé à la compilation.
Il y a au moins deux choses qui doivent faire l'objet d'un contrôle à l'exécution, pouvant déboucher sur une erreur de type: la conversion explicite et la manipulation de tableaux.
On peut demander à convertir un objet d'un type donné T vers un sous-type T' de T. Mais cela n'est possible en définitive que si le type constaté de l'objet est un sous-type de T'.
class A{
int x;
}
class B extends A{
int y;
}
...
A v1 = new B();
B v2 = (B) v1;
v3 = new A();
v4 = (B) v3;
Ici, on peut effectivement convertir v1 vers B. Ca ne pose pas de problème: v1 a déjà le champs y, créé par le new B(). La conversion est faite dynamiquement. Le type constaté de v1 ne change pas. C'est juste le type déclaré qui est changé, le temps de l'affectation.
En revanche v3 ne possède pas le champs y, puisqu'elle est créée par new A(). Cette variable ne peut donc pas être vue comme un objet de type B. La conversion est illégale. Pour être précis, ce bout de code est considéré comme valide à la compilation, mais pas à l'exécution. Il y a une erreur de typage à l'exécution.
La conversion de type est possible seulement si l'objet sans aucune modification peut être vu comme un objet du type désiré. Autrement dit, il n'y a pas vraiment de changement de l'objet, juste un changement de la manière de le voir.
Le problème vu avec un exemple:
class A{
...
}
class B extends A{
...
}
...
A x = new A();
A[] tab = new S[10];
tab[0] = x;
...
Tout ça est correct selon le système de types décrits jusqu'ici. Mais ça pose un vrai problème: un tableau dont un des éléments n'est pas d'un sous-type du type constaté du tableau.
Pour éviter ce problème, un test de type est effectué dans tous les cas d'affectation, avec prise en compte du type constaté du tableau. Ce type peut n'être connu qu'à l'exécution. Le test sera fait dynamiquement dans ces cas-là (et dans d'autres où le compilo n'est pas assez malin pour déterminer les types statiquement).
Sur un certain nombres de points, les concepteurs de JAVA ont choisi des solutions restrictives de façon à éviter des difficultés de typage et également des difficultés d'explication du typage.
Il n'y a pas de moyen de déclarer un objet ou un paramètre comme ayant le même type que this, quel que soit ce type.
C'est parfois gênant. Par exemple, quand on veut écrire les listes.
Palliatifs au problème: la possibilité d'utiliser le clonage et la conversion explicite de type.
JAVA ne permet pas de changer le type de méthodes dans une sous-classe ou une sous-interface. Si une méthode est déclarée avec le même nom et un type différent, elle est considérée comme une autre méthode et elle ne masque pas la première. Il s'agit de surcharge et non de masquage.
De ce fait, les problème de co-varaince et de contr-variance sont purement évités dans beaucoup de cas.
Cette définition simple permet d'éviter une description lourde et complexe. Mais elle conduit parfois à surtyper certaines méthodes.
Par exemple sur les listes. Si on décrit d'abord une classe de listes générales avec les méthodes cons, tete, queue, ces méthodes garderont le même type dans une sous-classe particulière (cf les EDs sur les listes).
Palliatif: la conversion explicite.
Par exemple, on ne peut pas décrire une structure de données paramétrées par le type des objets contenus. Listes, piles, etc.
Exception: les tableaux. On a vu que ce n'était pas très harmonieusement fait.
Palliatif: les conversions explicites. Exemple: Vector.
Les valeurs des types primitifs (int, boolean, float, ...) ne sont pas des objets. Cela pose parfois des problèmes. Un exemple: quand on veut utiliser les structures de données de la librairie JAVA, on ne peut mettre dedans que des objets. Pour rsoudre ce genre de difficultés, JAVA doubles les types primitifs par des classes permettant d'encapsuler les valeurs du types.
On a ainsi deux représentation différentes des entiers: int et la classe Integer. On peut faire des conversions de l'une à l'autre, mais ce n'est pas très agréable.
A toutes les subtilités de typage, JAVA offre la conversion explicite. Cela repousse la difficulté sur les épaules du programmeur qui doit savoir ce qu'il fait.
Ça se paie en efficacité (test dynamique).
On peut espérer une évolution favorable à l'avenir. En particulier, quelqu'un a proposé une extension conservative pour les classes paramétrées.
L'exemple suivant illustre toutes less difficultés mentionnées précédemment. Il s'agit d'une implémentation des listes chainées. Cette implémentation n'est pas très bonne à certains égards (en particulier la représentation de la liste vide). Elle ne doit pas être pris comme un exemple de la façon d'implémenter les listes mais comme une illustration des limitations de JAVA dues au typage.
class Liste implements Cloneable{
Object elem;
Liste suiv;
Liste(Object o, Liste l){
elem = o;
suiv = l;
}
static Liste listeVide(){
return new ListeVide();
}
Liste cons(Object o) throws Exception{
Liste l = (Liste) this.clone();
l.elem = o;
l.suiv = this;
return l;
}
Object premier() throws Exception{
return elem;
}
boolean testSiVide(){
return false;
}
Liste suivant() throws Exception{
return suiv;
}
public static void main(String[] argv) throws Exception{
Liste l = Liste.listeVide();
l = new Liste(new Integer(10),l);
for (int i = 0; i <10; i++)
l = l.cons(new Integer(i));
Liste k = l;
while (! k.testSiVide()){
System.out.println(((Integer) k.premier()).intValue());
k = k.suivant();
}
}
}
class ListeVide extends Liste{
ListeVide(){
super(null, null);
}
Exception e = new Exception();
Liste suivant() throws Exception{
throw e;
}
Object premier() throws Exception{
throw e;
}
boolean testSiVide(){
return true;
}
}
class ListeLg extends Liste{
int longu;
int longueur(){
return longu;
}
ListeLg(Object o, ListeLg l){
super(o,l);
}
Liste cons(Object o) throws Exception{
ListeLg l = (ListeLg) this.clone();
l.elem = o;
l.suiv = this;
l.longu = longu +1;
return l;
}
static Liste listeVide(){
return new ListeLgVide();
}
public static void main(String[] argv) throws Exception{
ListeLg l = (ListeLg) ListeLg.listeVide();
l = new ListeLg(new Integer(10),l);
for (int i = 0; i <10; i++)
l = (ListeLg) l.cons(new Integer(i));
Liste k = l;
while (! k.testSiVide()){
System.out.println(((Integer) k.premier()).intValue());
k = k.suivant();
}
((ListeLg) l.suivant()).longueur();
}
}
class ListeLgVide extends ListeLg{
ListeLgVide(){
super(null, null);
longu = 0;
}
Liste suivant() throws Exception{
throw new Exception();
}
Object premier() throws Exception{
throw new Exception();
}
boolean testSiVide(){
return true;
}
}
Nous allons commenter le code de la méthode main de
ListeLg.
Dès la première ligne, on voit que l'héritage pose un problème
de type pour la méthode listeVide. On voudrait que cette
méthode nous renvoie une valeur de type ListeLg. Or le type
déclaré est Liste. Le type constaté est
ListeLgVide, donc le code de la méthode aurait permis de
donner comme type déclaré le type ListeLg. Mais si on avait
fait cela, la méthode listeVide de ListeLg n'aurait
pas masqué la m{ethode listeVide de Liste et on
aurait eu de mauvaises surprises (absence de liaison retardée).
Donc, dès cette initialisation on est obligé de faire une conversion explicite.
Ce qu'on aurait voulu faire, c'est déclarer que la méthode
listeVide renvoie une valeur de même type que la classe
courante (à savoir Liste dans Liste et ListLg dans ListeLg). Une
telle chose est possible dans d'autres langages objets comme Eiffel,
mais pas en Java.
On voit aussi dans cet exemple que pour mettre des entiers (i) dans
une liste, on est obligé d'utiliser la classe Integer, avec
création d'un objet lorsqu'on insère un élément dans la liste
et conversion de type plus utilisation d'une méthode de conversion
intValue lorsqu'on retire un entier de la liste pour
l'imprimer. C'est particulièrement lourd.
Enfin, on voit bien dans tout le code de la méthode main, il
y a beaucoup de conversions explicites qui alourdissent le
texte. Une conversion explicite est le symptôme d'un
problème de typage, puisqu'un telle conversion ne change
rien au code, à la représentation réelle de l'objet en
mémoire, mais change juste son type pour permettre de
compiler le programme.
Dans le cas de Java, on peut facilement écrire un code tout à fait correct et qui a un sens mais qui ne passe pas au typage. Pour remédier à cela, il n'y a que la conversion explicite.
Notre cours insiste beaucoup sur un aspect des langages de programmation qui est le typage. C'est un aspect important du langage, puisque c'est la compréhension des mécanismes en cause qui permet d'écrire du code correct et en particulier de maitriser le concept-clé de la programmation objet, à savoir la liaison retardée.
Du point de vue du typage, le langage Java n'est pas très bien fait. Le choix effectué est la simplicité des règles de typage, au détriment de la puissance et au prix de vérifications dynamiques à l'exécution. La comparaison avec OCAML est assez éloquente: il est possible de faire beaucoup mieux que Java, au prix d'une certaine complexité.
Evidemment, le typage n'est pas le seul critère important pour juger la valeur d'un langage. A d'autres égards, Java est un bon langage. Ses points forts sont sa librairie standard qui est très riche et contient beaucoup de choses très utiles dans toute sortes de domaines (multimédia, réseau, interface graphique, etc). De ce point de vue, comme pour la diffusion et la notoriété, il l'emporte nettement sur OCAML.
Enfin, les deux langages possèdent des avantages communs par rapport à d'autres langages très utilisés comme C++, en particulier en termes de portabilité.