2.2. Autre petit compilateur
On considère un petit langage simple défini
comme suit:
<instruction> ::= <affectation> | <conditionnelle>
<conditionnelle> ::= ? <condition> : <affectation>
<condition> ::= <expression> {=|#} <expression>
<affectation> ::= <identificateur> = <expression>
<expression> ::= <facteur> {+|-} <expression> | <facteur>
<facteur> ::= <terme> {*|/} <facteur> | <terme>
<terme> ::= <identificateur> | <nombre> | ( <expression> )Les
identificateurs sont des unités lexicales constituées soit d'une
lettre unique, soit d'une lettre suivie d'un chiffre. Les nombres sont
également des unités lexicales constituées de chiffres; on
ne prend en compte que des entiers positifs ou nuls. Ces unités lexicales
peuvent donc être définies par les règles
suivantes:
<identificateur> ::= <lettre> | <lettre><chiffre>
<nombre> ::= <chiffre><nombre> | <chiffre>
Les
espaces ne peuvent se trouver à l'intérieur d'une unité
lexicale, et n'ont pas de signification. Une instruction doit se trouver toute
entière sur une seule ligne, et une ligne ne peut contenir qu'une seule
instruction.
A- L'analyse lexicale consiste à reconnaître
la suite des unités lexicales d'une ligne, et à fournir la suite
des codes syntaxiques de ces unités lexicales. Elle doit donc fournir une
suite d'entiers correspondant à ces codes, de la façon
suivante:
- Pour un nombre, le code est la valeur de
l'entier correspondant.
- Pour un identificateur,
le code est l'entier négatif, compris entre -286 et -1, ayant pour valeur
-numéro_de_lettre si
l'identificateur est composé d'une seule lettre, et
-(numéro_de_lettre+26*(chiffre+1)),
s'il est composé d'une lettre et d'un
chiffre.
- Pour un caractère spécial,
le code associé est défini par la table
suivante:
|
caractère
|
=
|
(
|
)
|
+
|
-
|
*
|
|
code
|
-287
|
-288
|
-289
|
-290
|
-291
|
-292
|
|
caractère
|
/
|
?
|
:
|
#
|
K_fin_ligne
|
|
code
|
-293
|
-294
|
-295
|
-296
|
-297
|
A.1- Donner le résultat fourni par l'analyseur
lexical pour les lignes suivantes:
A1 = A * 100 + 2*B
A1 = A + 100 * B-C
? A1 = B : C = D
A.2- Donner le résultat fourni par l'analyseur
lexical pour les lignes suivantes:
?A=3
AB=32
A.3- Que doit indiquer l'analyseur lexical pour la ligne
suivante:
A = 2 ! 3
B- L'analyse syntaxique consiste à vérifier
la concordance de la suite des codes syntaxiques telle qu'elle résulte de
l'analyse lexicale avec les règles de syntaxe du langage. Elle permet
aussi de retrouver la structure syntaxique du "programme".
B.1- Donner la structure syntaxique pour chacune des
lignes suivantes:
A1 = A * 100 + 2*B
A1 = A + 100 * B-C
? A1 = B : C = D
B.2- Expliquer pourquoi chacune des lignes suivantes est
syntaxiquement erronée:
?A=3
AB=32
B.3- Pourquoi n'y a-t-il pas lieu de faire l'analyse
syntaxique de la ligne suivante:
A = 2 ! 3
Solution de l’exercice
2.2
2.2.1. Question A
2.2.1.1. Question A.1
Le résultat de l'analyse lexicale est le
suivant:
|
Pour :
|
Le codage obtenu est :
|
|
A1 = A * 100 + 2*B
|
-53, -287, -1, -292, 100, -290, 2, -292, -2, -297
|
|
A1 = A + 100 * B-C
|
-53, -287, -1, -290, 100, -292, -2, -291, -3, -297
|
|
? A1 = B : C = D
|
-294, -53, -287, -2, -295, -3, -287, -4, -297
|
2.2.1.2. Question A.2
Le résultat de l'analyse lexicale est le
suivant:
|
Pour :
|
Le codage obtenu est :
|
|
?A=3
|
-294, -1, -287, 3, -297
|
|
AB=32
|
-1, -2, -287, 32, -297
|
Comme un identificateur est constitué d'une lettre
seule, ou d'une lettre suivie d'un chiffre, la présence ici de deux
lettres qui se suivent est interprété, lexicalement, comme une
succession de deux identificateurs.
2.2.1.3. Question A.3
Lors de l'analyse de la phrase "A = 2 ! 3", on constate la
présence d'un caractère qui ne fait partie d'aucun symbole de
notre langage. Il s'agit donc d'une erreur lexicale.
2.2.2. Question B
2.2.2.1. Question B.1
Retrouver la structure syntaxique consiste à retrouver
les règles de productions qui ont été utilisées pour
construire la phrase. Évidemment, on peut utiliser les algorithmes
donnés dans le problème 17.1 du livre, adaptés en fonction
des quelques modifications apportées au langage. C'est ce que fera
l'analyseur syntaxique. On peut aussi raisonner de façon apparemment plus
intuitive, mais en fait analogue à l'algorithme de l'analyseur, en
essayant de "deviner" les règles utilisées.
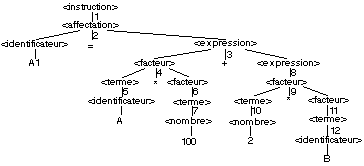
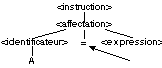
Pour A1 = A * 100 + 2*B, on cherche à développer
<instruction>, en utilisant l'une des
règles possibles, qu'il faut essayer successivement, en cas de refus,
jusqu'à trouver le bon choix. On développe donc
1 <instruction> ::= <affectation>
2 <affectation> ::= <identificateur> = <expression>
qui
permet d'accepter "A1 =". Ensuite, on utilise successivement les
règles
3 <expression> ::= <facteur> {+|-} <expression> | <facteur>
4 <facteur> ::= <terme> {*|/} <facteur> | <terme>
5 <terme> ::= <identificateur> | <nombre> | ( <expression> )permettant
d'accepter "A". Le retour sur la règle 4 définissant
<facteur> conduit ensuite à
accepter "*", et à développer les règles
6 <facteur> ::= <terme> {*|/} <facteur> | <terme>
7 <terme> ::= <identificateur> | <nombre> | ( <expression> )qui
conclut sur le nombre 100. Cette fois le retour sur la règle 6
définissant <facteur> conduit
à la terminaison de cette règle, puis à la terminaison de
la règle 4, permettant alors l'acceptation du "+". On développe
alors les règles
8 <expression> ::= <facteur> {+|-} <expression> | <facteur>
9 <facteur> ::= <terme> {*|/} <facteur> | <terme>
10 <terme> ::= <identificateur> | <nombre> | ( <expression> )permettant
d'accepter "2". Le retour sur la règle 9 définissant
<facteur> conduit ensuite à
accepter "*", et à développer les règles
11 <facteur> ::= <terme> {*|/} <facteur> | <terme>
12 <terme> ::= <identificateur> | <nombre> | ( <expression> )qui
conclut sur l'identificateur B. Le retour sur la règle 11 conduit
à la terminer, impliquant la terminaison de la règle 9. Le retour
sur la règle 8 conduit également à la terminer, impliquant
la terminaison des règles 3 puis 2 puis 1, et ensuite à
l'acceptation de K_fin_ligne, et
l'acceptation finale de la phrase. La structure syntaxique est donc:
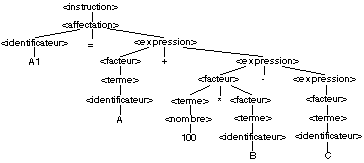
Pour A1 = A + 100 * B-C, nous obtenons
Pour ? A1 = B : C = D, nous obtenons
2.2.2.2. Question B.2
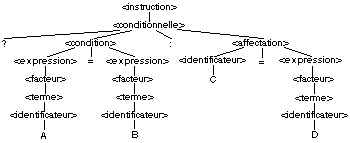
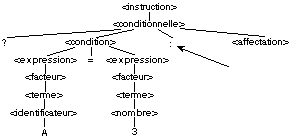
Pour la phrase ?A=3, l'analyseur syntaxique commence à
construire la structure suivante
Lorsqu'il vérifie que le symbole est ':', il trouve en
fait K_fin_ligne. Comme il n'a pas d'autre
choix possible, il indique une erreur syntaxique.
Pour la phrase AB=32, rappelons d'abord que l'analyseur
lexical l'a transformée en suite de symboles codés -1, -2, -287,
32, -297. Ceci montre bien la présence de deux identificateurs qui se
suivent. L'analyseur syntaxique commence à construire la structure
suivante
Lorsqu'il vérifie que le symbole est '=', il trouve en
fait l'identificateur 'B'. Comme il n'a pas d'autre choix possible, il indique
une erreur syntaxique.
2.2.2.3. Question B.3
La phrase A = 2 ! 3 étant
erronée lexicalement, il est inutile d'en faire l'analyse syntaxique. De
fait, le caractère '!' ne correspondant à aucun symbole, ne peut
être codé.
Notons que dans certains cas, pour permettre de trouver le
maximum d'erreurs le plus vite possible, l'analyseur lexical ignorera ce
caractère après avoir signalé l'erreur. Il transmettra
à l'analyseur syntaxique la suite codée, comme s'il n'existait
pas.