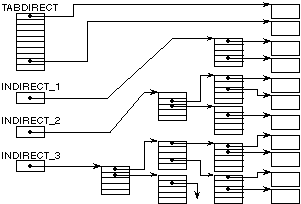
3.7. Gestion de fichiers UNIX
Le paragraphe 8.3.2 du cours définit la localisation
d'un fichier UNIX par (figure ci-dessous):
- une table, que nous appelons TABDIRECT, donnant
les numéros de blocs pour les 10 premiers blocs de l'objet
externe,
- un numéro de bloc, que nous
appelons INDIRECT_1, qui contiendra les numéros des p blocs suivants de
l'objet externe,
- un numéro de bloc, que
nous appelons INDIRECT_2, qui contiendra les p numéros de blocs contenant
les numéros des p2 blocs suivants de l'objet
externe,
- un numéro de bloc, que nous
appelons INDIRECT_3, qui contiendra les p numéros de blocs contenant, au
total, p2 numéros de blocs contenant les numéros des
p3 blocs suivants de l'objet
externe.
Nous supposerons que les blocs sont de 1024 octets, et qu'un
numéro de bloc occupe 4 octets. Il s'ensuit que p = 256. Par ailleurs, le
temps d'accès moyen au disque est de 40 ms.
A- Un processus lit séquentiellement un fichier de
8 Mo, à raison de 256 octets à la fois. Il fait donc 32768
demandes de lecture successives. On suppose qu'il n'y a qu'un seul processus
dans le système, et que le système n'utilise pas de tampons de
bloc disque, ce qui implique que chaque fois qu'une information située
dans un bloc disque est nécessaire, ce bloc doit être lu depuis le
disque. Évidemment le descripteur d'un fichier ouvert,
c'est-à-dire les informations
TABDIRECT,
INDIRECT_1,
INDIRECT_2 et
INDIRECT_3, restent en mémoire
centrale.
A.1- Décrire ce qui se passe lors des deux
premières demandes de lecture de 256 octets, puis lors de la
5ième demande.
A.2- Décrire ce qui se passe lors des
41ième et 45ième demandes de lecture de 256
octets.
A.3- Décrire ce qui se passe lors des
1065ième et 1066ième demandes de lecture de
256 octets.
A.4- Décrire ce qui se passe lors des
2089ième et 2090ième demandes de lecture de
256 octets.
A.5- En déduire le nombre total d'accès
disque nécessaires et le temps d'attente
d'entrées-sorties.
B- Il est dit dans le cours (§8.3.2) qu'Unix utilise
une technique de cache des blocs disques. Pour cela, le système dispose
d'un tableau de 100 tampons en mémoire centrale, dans lesquels il peut
conserver 100 blocs de disque. Lorsque le système a besoin d'un bloc
disque, pour lui-même ou pour le compte d'un processus, il recherche dans
ces tampons si ce bloc n'est pas déjà en mémoire. S'il n'y
est pas, alors, si aucun tampon n'est libre, il commence par en libérer
un suivant un algorithme analogue à l'algorithme de remplacement de pages
LRU, puis lit le bloc dans un tampon libre et effectue le traitement sur ce
bloc. En particulier, lorsqu'un processus demande la lecture ou
l'écriture d'octets, le système détermine le bloc disque
qui les contient, et lorsque ce bloc est dans un tampon, il réalise le
transfert demandé: lecture des octets depuis le tampon ou écriture
des octets dans le tampon.
B.1- Les tampons sont dans l'espace du système, et
sont partagés entre tous les processus, et non dans l'espace propre de
chacun. Expliquez quelles sont à votre avis les raisons de ce
choix.
B.2- En supposant les tampons initialement vides,
reprendre l'exemple de la question A d'un processus (toujours seul dans le
système) lisant séquentiellement un fichier de 8 Mo, à
raison de 256 octets à la fois, et décrire ce qui se passe lors
des demandes de lecture 1, 2, 5, 41, 45, 1065, 1066, 2089, 2090. En
déduire le nombre total d'accès disque nécessaires et le
temps d'attente d'entrées-sorties.
C- Le système fonctionne comme en B, et un
processus écrit séquentiellement un fichier de 8 Mo, à
raison de 256 octets à la fois. On suppose que l'espace disque est
déjà complètement alloué au fichier.
C.1- Si on suppose que le système
réécrit un tampon sur disque chaque fois qu'il est modifié,
évaluez le nombre d'accès disque nécessaires et le temps
d'attente d'entrées-sorties.
C.2- Même question qu'en C.1, mais en supposant
maintenant qu'un tampon modifié est réécrit sur disque
uniquement lorsqu'il y a remplacement. Quels sont les avantages et les
inconvénients de cette méthode?
C.3- Expliquer l'intérêt de la primitive
système sync qui force la
réécriture sur disque de tous les tampons modifiés. A votre
avis, quand cette primitive doit-elle être appelée?
D- Sur certains systèmes autre que Unix, les
contrôleurs disques sont dotés de mémoires caches, de
technologie voisine de celle des mémoires centrales, et qui peuvent
contenir plusieurs pistes indépendantes. Quelle analogie voyez-vous avec
ce qui précède? Si le système implante les objets externes
en utilisant une allocation par zone, quel choix de quantum vous paraît
alors judicieux?
Solution de l'exercice
3.7.
3.7.1. Question A
3.7.1.1. Question A.1
Lors de la première demande de lecture, le descripteur
de fichier contient en TABDIRECT[0] le
numéro du premier bloc de données. Il faut donc le lire, et
transférer les 256 premiers octets (disons ceux de numéro 0
à 255) de ce bloc dans une zone du programme. Lors de la deuxième
demande, il s'agit du même bloc, mais comme il n'y a pas de conservation
dans un tampon des blocs, il faut le relire, et délivrer les octets 256
à 511. Pour la cinquième demande, il s'agit des octets 0 à
255 du deuxième bloc de données, c'est-à-dire, le bloc de
numéro TABDIRECT[1].
3.7.1.2. Question A.2
Les octets de la 41ième demande sont
situés dans le 11ième bloc de données. Il faut
donc lire le bloc INDIRECT_1 pour
connaître le numéro du bloc de données qui nous
intéresse (premier numéro de bloc dans ce bloc), et pouvoir lire
celui-ci. Les octets de la 45ième demande sont situés
dans le 12ième bloc de données. Il faut donc aussi lire
le bloc INDIRECT_1 pour connaître le
numéro du bloc de données qui nous intéresse
(deuxième numéro de bloc dans ce bloc), et pouvoir lire celui-ci.
Il s'ensuit que chaque demande de lecture, à partir de maintenant
entraînera deux accès disque.
3.7.1.3. Question A.3
Les octets de la 1065ième demande sont
situés dans le 266ième bloc de données. Il faut
donc lire le bloc INDIRECT_2, puis celui
dont le numéro est le premier dans le bloc venant d'être lu, pour
avoir le numéro du bloc de données qui nous intéresse
(premier numéro de bloc dans celui venant d'être lu), et lire enfin
le bloc de données. Les octets de la 1066ième demande
sont situés également dans le 266ième bloc de
données. En l'absence de mémorisation, il faudra relire les
mêmes blocs que précédemment pour satisfaire la demande. On
peut donc en conclure que dorénavant, 3 accès disque seront
nécessaires pour satisfaire chaque demande.
3.7.1.4. Question A.4
Les octets de la 2089ième sont situés
dans le 522ième bloc de données. Il faut donc lire le
bloc INDIRECT_2, puis celui dont le
numéro est le deuxième dans le bloc venant d'être lu,
pour avoir le numéro du bloc de données qui nous intéresse
(premier numéro de bloc dans celui venant d'être lu), et lire enfin
le bloc de données. Les octets de la 2090ième demande
sont situés également dans le 522ième bloc de
données. En l'absence de mémorisation, il faudra relire les
mêmes blocs que précédemment pour satisfaire la demande. On
peut donc en conclure que 3 accès disque sont toujours nécessaires
pour satisfaire chaque demande.
3.7.1.5. Question A.5
Les 40 premières demandes de lecture demanderont
chacune un accès disque. Les 1024 suivantes en demanderont chacune deux.
Les demandes restantes (32768 - 1024 - 40 = 31704)
en demanderont chacune trois. On a donc un total de 97200 accès disque,
et un temps d'attente d'entrées-sorties de 3888 secondes, soit un peu
plus d'une heure. Notons que l'indirection de niveau 3 n'est pas utilisée
puisque 2 niveaux permettent de mémoriser 65 Mo, alors que nous n'en
avons que 8 Mo.
3.7.2. Question B
3.7.2.1. Question B.1
Plusieurs raisons justifient que les tampons soient dans
d'espace système, et soient ainsi partagés par tous les processus.
Tout d'abord, mentionnons une raison d'économie: s'il fallait
réserver des tampons pour chaque processus, il y aurait perte de place
pour ceux qui n'accèdent à aucun fichier, et manque de place pour
les autres. Le partage de l'espace permet d'attribuer les tampons lorsque
nécessaires.
Cependant, la raison essentielle est liée aux
accès simultanés à un même fichier par plusieurs
processus. Si plusieurs processus cherchent à lire dans le même
fichier, le partage permet de diminuer les accès disque, puisque une
lecture d'un bloc dans un tampon partagé pour le compte d'un processus
évitera la lecture de ce même bloc pour le compte d'un autre
processus. Par ailleurs, si les tampons étaient propres aux processus,
une écriture (opération
write) par un processus sur le fichier,
serait en fait une écriture dans ses propres tampons et son effet ne
serait visible aux autres processus que plus tard, à un moment
imprévisible. La technique de cache des blocs disques doit en fait
être “transparente” aux utilisateurs. Les processus manipulent
des flots par les opérations read et
write. L'implantation de ces
opérations doit respecter la “sémantique” attendue par
leur spécification. L'effet sur le contenu du fichier doit être
immédiatement visible par les autres processus (la cohérence des
données est du ressort de la synchronisation entre les
processus).
3.7.2.2. Question B.2
L'utilisation d'un algorithme LRU pour la gestion des tampons
signifie que chaque accès à un tampon place celui-ci en tête
de liste. Contrairement à la question A, le besoin d'une information
située dans un bloc disque ne demande pas d'accès disque, si ce
bloc est déjà présent dans un tampon. En reprenant le
raisonnement de la question A, on constate que si la première demande,
comme la cinquième, demande un accès disque pour obtenir le bloc,
par contre la seconde n'en demande pas, puisque le bloc a été
conservé dans un tampon. Plus généralement, les 40
premières demandes ne demandent que 10 accès disques pour obtenir
les 10 blocs concernés qui tiennent amplement dans les 100
tampons.
Lors de la 41ièmedemande, il faut lire le
bloc pointeur de numéro INDIRECT_1
dans un tampon, puisqu'une information qui y est contenue (le numéro du
bloc de données) est nécessaire. Il faut ensuite lire le bloc de
données lui-même. Notons que pour les 3 demandes suivantes, aucun
accès n'est nécessaire, puisque les informations sont dans les
tampons. Lors de la 45ième demande, le bloc pointeur de
numéro INDIRECT_1 est
déjà dans un tampon, et il est alors placé en tête de
liste LRU. Le bloc de données est alors lu et placé devant lui
dans cette liste. Plus généralement, après chaque demande
de lecture (jusqu'à la 1064ième comprise), le bloc de
données qui était concerné se trouve en tête de liste
LRU, suivi immédiatement par le bloc
INDIRECT_1. On peut donc en conclure que
les 1024 demandes (41 à 1064) nécessitent 257 accès disque
(le bloc INDIRECT_1 et les 256 blocs de
données).
Lors de la 1065ième demande, il faut lire le
bloc INDIRECT_2, puis le bloc pointeur dont
le numéro est le premier dans le bloc
INDIRECT_2, et enfin le bloc de
données. Lors de la 1066ième demande, les mêmes
blocs sont nécessaires, mais aucun accès n'a lieu, puisqu'ils sont
présents dans les tampons. Ici encore, après chaque demande, on
constate que le bloc de données est en tête de la liste LRU, suivi
du bloc pointeur dont le numéro est le premier du bloc
INDIRECT_2, suivi du bloc
INDIRECT_2. Ces blocs pointeurs resteront
en mémoire au moins jusqu'à la 2089ième demande.
Les demandes 1065 à 2088 demanderont donc 258 accès disques (le
bloc INDIRECT_2, le premier bloc pointeur
et les 256 blocs de données).
Lors de la 2089ième demande, on a besoin du
bloc INDIRECT_2, toujours présent en
mémoire, puis du bloc pointeur dont le numéro est le
deuxième dans le bloc INDIRECT_2,
qui doit donc être lu, et enfin du bloc de données. Ces mêmes
blocs seront nécessaires pour la demande 2090. Ici encore, on constate
qu'après chaque demande, le bloc de données est en tête de
la liste LRU, suivi par le bloc pointeur, suivi par le bloc
INDIRECT_2. Les 1024 demandes suivantes
(2089 à 3112) demanderont donc 257 accès disques (un bloc pointeur
et 256 blocs de données), et ainsi de suite.
En résumé, nous avons:
40 demandes avec 10 accès disques
1024 demandes avec 1+256 accès disques
30720 (30*1024) demandes avec 1+30*(1+256) accès
disques
984 (32768-40-1024-30720) demandes avec 1+246 accès
disques (984/4).
Soit un total de 8225 accès disque, qui se
décomposent en 8192 lectures de blocs de données et 33 lectures de
blocs pointeurs de blocs. Ceci donne un temps d'attente de 329 secondes, ou 5.5
minutes. Par rapport à la question A, le nombre d'accès disques a
été divisé par environ 12! On pouvait s'y attendre: en A,
chaque demande en double indirection, c'est-à-dire, les plus nombreuses,
demandait la lecture de 3 blocs, alors que maintenant il y a environ une lecture
toutes les 4 demandes.
Notons que LRU permet de replacer en début de liste les
blocs pointeurs utilisés, ce qui entraîne sur notre exemple que ces
blocs ne sont lus qu'une seule fois. Avec l'algorithme FIFO, après avoir
lu environ 100 blocs de données repérés par le même
bloc pointeur, ce dernier serait chassé de la mémoire pour y
être rappelé lors de la demande suivante. Il y aurait donc un peu
plus d'accès disque.
3.7.3. Question C
3.7.3.1. Question C.1
Le raisonnement de la question précédente peut
s'appliquer également au cas où un processus écrit
séquentiellement un fichier. Comme on suppose que l'espace disque est
déjà complètement alloué au fichier, lors d'une
demande d'écriture de 256 octets, soit le bloc est déjà
dans un tampon, soit il s'agit du premier accès à ce bloc, ce qui
implique sa lecture préalable puisque la modification est partielle. On
peut donc considérer que toute demande d'écriture est identique
à une demande de lecture suivie d'une modification du tampon et d'une
écriture sur disque du bloc de données. En d'autres termes, on
aura le même nombre d'accès disque que précédemment
pour les lectures (soit 8225) augmenté des accès disque pour les
écritures, soit 32768. Nous avons donc un total de 40993 accès
disque, donnant un temps d'attente pour entrées-sorties de 1640 secondes,
soit un peu plus de 27 minutes.
3.7.3.2. Question C.2
Si on suppose que les tampons ne sont écrits que lors
du remplacement, comme nous avons vu en B qu'un bloc de données n'est lu
qu'une seule fois, cela signifie qu'il n'est plus accédé
après le premier remplacement dont il fait l'objet (et le seul). Il
s'ensuit que chaque bloc de données est écrit exactement une fois.
Il n'y a donc plus que 8192 accès disque pour écriture, et donc un
total de 16417 accès disque, donnant un temps d'attente de 657 secondes,
soit environ 11 minutes.
L'avantage de cette méthode est évidente de par
le résultat ci-dessus, puisque le temps d'attente passe de 27 minutes
à 11 minutes, soit un gain de 60%. L'inconvénient principal
réside dans le risque de ne pas avoir un contenu de fichier
cohérent en cas de panne. En effet, si une panne de courant, ou un
plantage du système, survient alors que tous les tampons qui ont
été modifiés en mémoire centrale n'ont pas encore
été réécrits sur disque, il est difficile de savoir
dans quel état sont les données. Pour un utilisateur, il peut
croire le fichier entièrement modifié, car le processus est
terminé, alors qu'il reste une centaine de blocs à
réécrire! Si le programme prévoit des affichages
intermédiaires pour informer l'utilisateur de l'état d'avancement
de l'écriture, on constate que cette information est en fait partielle:
les 400 dernières opérations ne sont peut-être pas encore
effectives.
Par ailleurs, si tous les processus arrêtent leur
activité sur les fichiers, il n'y a plus de remplacement, donc pas
d'écriture des derniers blocs actuellement dans les tampons. Si on coupe
alors le courant, le contenu de ces derniers blocs sont perdus.
3.7.3.3. Question C.3
La primitive système
sync garantit, après son
exécution, que le disque est cohérent, à ce moment, avec
toutes les modifications qui ont été faites par les processus. Il
faut donc l'appeler chaque fois que l'on désire avoir cette
cohérence. On peut l'appeler périodiquement, par exemple, toutes
les 30 secondes, pour se prémunir contre les longues périodes
d'inactivités. On doit l'appeler avant d'éteindre le
système pour garantir la cohérence des disques avec les
dernières modifications. On peut l'appeler lors de la fermeture du
fichier (mais c'est souvent fait implicitement par le système).
3.7.4. Question D
Lorsque les contrôleurs disques sont dotés de
mémoires caches pouvant contenir plusieurs pistes indépendantes,
cela veut dire que toute demande de lecture d'un secteur quelconque
entraîne d'abord la lecture de la piste complète qui le contient
dans une portion de cette mémoire cache, puis le transfert du (ou des)
secteur demandé dans la mémoire centrale. La mémoire cache
joue le rôle des tampons des questions B et C, le bloc étant alors
l'équivalent d'une piste. Il s'ensuit que la lecture d'un secteur
situé dans une piste déjà présente dans la
mémoire cache ne nécessite aucun accès disque, mais
seulement le transfert des données entre la mémoire cache et la
mémoire centrale. Si ce transfert n'est pas instantané, il peut
cependant se faire en, par exemple, 200 μs pour 1 Ko.
Pour améliorer la probabilité que, lors d'une
demande, le secteur soit présent dans la mémoire cache, il est
préférable qu'une piste contienne des informations appartenant
à un seul fichier, plutôt qu'à plusieurs fichiers. Ceci peut
être obtenu avec une allocation par zone lorsque les zones sont
allouées par pistes entières, et donc si le quantum est un nombre
entier de pistes. En particulier, on pourra prendre un quantum de une piste, si
cela ne conduit pas à un nombre trop important de quanta.