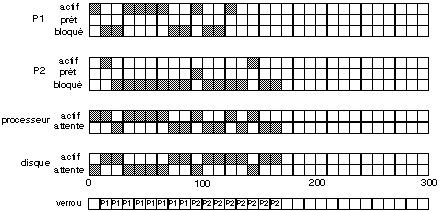
L’analyse lexicale a pour but de retrouver les symboles utilisés par le programmeur à partir de la suite de caractères du texte source. Pour cela, lorsque l’on est sur le premier caractère d’un symbole, on recherche où il finit, selon la définition de la structure lexicale du langage. Puis, l’ayant reconnu, il est en général codé pour la suite des traitements. Ensuite, on recherche où commence le symbole suivant,
Pour l’analyse lexicale de la première phrase Truc and A = 23, on commence donc par se positionner sur le premier caractère du premier symbole, c’est-à-dire T. S’agissant d’une lettre, c’est donc le début d’un identificateur ou d’un mot clé. La fin est donc obtenue lorsque l’on rencontre un caractère qui n’est pas une lettre, c’est-à-dire l’espace qui suit c. Notre premier symbole est donc l’identificateur Truc. La recherche du début du symbole suivant nous conduit à sauter l’espace sans signification et le symbole suivant commence sur le a. Comme précédemment, il s’agit d’un identificateur ou d’un mot réservé, qui se termine sur le d précédant l’espace. Nous avons donc le mot réservé and. De même, on isole le symbole suivant qui est l’identificateur A. Ensuite, la recherche du début du symbole suivant nous conduit sur le caractère = qui constitue à lui seul un symbole. Enfin, le symbole suivant commence sur le caractère 2. Il s’agit donc d’un entier qui se termine sur le premier caractère qui n’est pas un chiffre, donc sur la fin de la ligne, et le dernier symbole est donc 23. Nous avons donc le découpage suivant :
Truc and A = 23
L’analyse de la ligne suivante nous permet d’isoler d’abord le mot réservé not, puis l’identificateur C et le symbole =. Ensuite, le symbole suivant commence sur le 1 qui est un chiffre et s’arrête donc sur le premier caractère qui n’est pas un chiffre, donc le point. Nous obtenons le symbole entier 1. Le symbole suivant commence sur le point, qui n’appartient pas à l’ensemble des caractères du langage. Il y a donc erreur syntaxique, et l’analyse s’arrête.
not C = 1.2
Les lignes suivantes ne posent guère de difficulté, et s’analysent comme nous l’avons détaillé précédemment. Nous obtenons les découpages suivants :
A = 12 or 13
A not B
Notons que ce n’est pas à l’analyse lexicale de trouver les erreurs syntaxiques ou sémantiques.
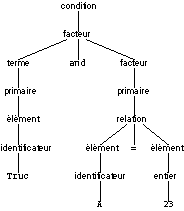
L’analyse syntaxique a pour but de retrouver les règles de syntaxe utilisées par le programmeur pour construire la suite de symboles. Nous partons donc maintenant de la suite de symboles obtenue après analyse lexicale, lorsque celle-ci est correcte, pour trouver les règles utilisées. La première règle part de <condition>, et le développement doit nous permettre d’aboutir aux symboles eux-mêmes de la phrase analysée. On peut représenter cette suite par un arbre qui décrit ainsi la structure syntaxique de la phrase.
Pour les deux premières phrases, l’analyse est relativement simple. Elle peut être effectuée comme cela a été fait dans les exercices 2.1 et 2.2 du polycopié d’exercices. On cherche à développer <condition> en utilisant l’une des règles possibles, qu’il faut essayer successivement, en cas de refus, jusqu’à trouver le bon choix, ou déceler l’erreur syntaxique s’il n’y en a plus. On obtient les deux arbres suivants.
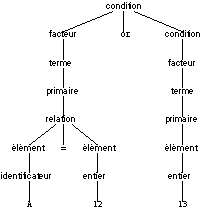
Pour la troisième, on effectue le développement de la même façon, et nous obtenons :
<condition> -> <facteur> -> <terme> -> <primaire> -> <élément> -> <identificateur> -> A
A ce stade, la phrase continue, mais l’analyse ne peut se poursuivre. Il faudrait donc trouver un autre développement, qui n’existe pas. Il y a donc erreur syntaxique sur le symbole not.
L’analyse sémantique a pour but de retouver le sens de la phrase, et de déterminer ainsi la suite des opérations à effectuer sur les données. Pour cela, on utilise la structure syntaxique obtenue précédemment. On détermine, d’abord les objets manipulés et leurs propriétés. Ensuite, on reporte ces informations dans le graphe, en propageant les propriétés, et en contrôlant leur cohérence. On détermine ainsi la signification des opérations.
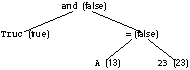
Ainsi, pour la première phrase, il y a trois objets Truc (booléen), A (entier) et 23 (entier). En propageant le type entier des deux derniers, on en déduit que l’égalité est l’opération entre entiers, avec un résultat booléen. La propagation au niveau de l’opérateur and montre la cohérence de l’ensemble.
Le graphe suivant décrit les opérations à effectuer. Les valeurs des opérandes et du résultat sont mis entre paranthèses.
De même, pour la deuxième phrase, il y a aussi 3 objets, tous trois entiers, que sont A, 12 et 13. En propageant le type entier des deux premiers, on en déduit que l’égalité est l’opération entre entiers, avec un résultat booléen. La poursuite de la propagation montre la cohérence de type pour l’opérande de gauche de or. La propagation du type entier du troisième objet montre une incohérence de type pour l’opérande de droite de or (on a un type entier alors qu’on attend un type booléen). On décèle ainsi une erreur sémantique pour la deuxième phrase.
Dans le système FAT, il y a deux contraintes : il ne peut y avoir plus de 65535 clusters, et le cluster ne peut dépasser 255 secteurs. Le disque comportant 222 secteurs, si on veut que la taille d’un cluster soit une puissance de 2, il ne peut dépasser 128 secteurs. Le choix proposé est donc cohérent avec les contraintes, puis que l’on a alors 32768 clusters. Notons qu’une taille de 64 secteurs serait néanmoins acceptable, sous réserve de ne pas disposer de tout l’espace, puisqu’il nous faudrait 65536 clusters, et qu’il faut pouvoir coder la fin de fichier et l’état libre des clusters.
Dans ces conditions, une piste contient 2 clusters, et un cylindre en contient 8. L’espace alloué au fichier est donc constitué des clusters suivants dans l’ordre : 256, 257, 387, 516, 517, 130, 134, 135. Cela veut dire que le descripteur du fichier contient le numéro de cluster 256 (le premier), et dans la FAT proprement dite, on a les valeurs suivantes pour les entrées de numéro indiqué.
|
index |
256 |
257 |
387 |
516 |
517 |
130 |
134 |
135 |
|
valeur |
257 |
387 |
516 |
517 |
130 |
134 |
135 |
EOF |
Pour accéder à un secteur logique de numéro ni du fichier, on commence par rechercher le cluster auquel il appartient, en divisant ce numéro par la taille du cluster en secteurs, c’est-à-dire 128. On parcours ensuite la FAT jusqu’à trouver le cluster physique correspondant. On détrermine ainsi le numéro virtuel du secteur recherché, que l’on transforme en triplet <nc, nf, ns> prenant en compte la linéarisation de l’espace.
Pour le secteur 5, il s’agit dont du secteur relatif 5 du cluster logique 0, qui correspond au cluster physique 256. Il s’agit donc du secteur virtuel 256*128+5=32773. Il s’agit donc du secteur relatif 32773 mod 1024=5 du cylindre 32773/1024=32, et donc du secteur 5 de la face 0 du cylindre 32. On a donc le triplet <32, 0, 5>.
Pour le secteur 100, il s’agit du secteur relatif 100 du cluster logique 0, donc le secteur virtuel 256*128+100=32868. C’est donc cette fois le secteur 100 du cylindre 32, et donc le secteur 100 de la face 0 du cylindre 32, soit <32, 0, 100>
Pour le secteur 800, il s’agit du secteur relatif 800 mod 128= 32 du cluster logique 800/128=6. Le parcours de la FAT nous donne 256 (0)->257 (1)->387 (2)->516 (3)->517 (4)->130 (5)->134 (6). Il s’agit donc du secteur 32 du cluster physique 134, soit le secteur virtuel 134*128+32=17184. C’est donc le secteur relatif 17384 mod 1024=800 du cylindre 17384/1024=16, qui est le secteur 800 mod 256=32 de la piste située sur la face 800/256=3. On a donc le triplet <16, 3, 32>
Dans le système HFS, on a les mêmes contraintes pour la taille du quantum que pour la taille du cluster du système FAT. La justification d’une taille de quantum de 128 secteurs est donc la même.
Dans HFS, l’allocation est par zones de taille variable. Les données montrent l’existence de 5 zones, qui peuvent être décrites comme suit : <256, 2>, <387, 1>, <516, 2>, <130, 1>, <134, 2>, où le premier nombre indique le premier bloc physique de la zone et le deuxième le nombre de blocs de la zone. Le descripteur de fichier lui-même contient la description des trois premières zones, c’est-à-dire :
Le fichier de description des extensions contiendra la description des deux autres zones. Ce fichier contiendra donc un article constitué des éléments suivants :
Pour accéder à un secteur logique de numéro ni du fichier, il faut déterminer le numéro du bloc logique auquel il appartient et la position relative du secteur logique dans ce bloc (quotient et reste da la division par 128 ici), puis rechercher la zone à la quelle appartient ce bloc logique, en parcourant la liste des zones. Lorsque l’on a trouvé la zone, et donc le numéro du premier bloc physique de la zone, on détermine alors le numéro virtuel du secteur recherché, que l’on transforme en triplet <nc, nf, ns> prenant en compte la linéarisation de l’espace.
Pour le secteur 5, il s’agit du secteur relatif 5 du bloc logique 0, qui est le premier bloc de la première zone, qui commence au bloc physique 256. Il s’agit donc du secteur virtuel 256*128+5=32773. Il s’agit donc du secteur relatif 32773 mod 1024=5 du cylindre 32773/1024=32, et donc du secteur 5 de la face 0 du cylindre 32. On a donc le triplet <32, 0, 5>.
Pour le secteur 100, il s’agit du secteur relatif 100 du bloc logique 0, donc le secteur virtuel 256*128+100=32868. C’est donc cette fois le secteur 100 du cylindre 32, et donc le secteur 100 de la face 0 du cylindre 32, soit <32, 0, 100>
Pour le secteur 800, il s’agit du secteur relatif 32 du bloc logique 6. Ce bloc n’est pas dans la première zone qui contient les bloc logiques 0 et 1, ni dans la seconde qui contient le bloc logique 2, ni dans la troisième qui contient les blocs logiques 3 et 4. Un accès au fichier de descriptions des extensions nous fournit la description des quatrième et cinquième zones. Le bloc n’est pas non plus dans la quatrième zone qui contient le bloc 5. On constate que le bloc 6 est donc le premier bloc de la cinquième zone, qui commence au bloc physique 134. Le secteur recherché est donc le secteur virtuel 134*128+32=17384. C’est donc le secteur relatif 17384 mod 1024=800 du cylindre 17384/1024=16, qui est le secteur 800 mod 256=32 de la piste située sur la face 800/256=3. On a donc le triplet <16, 3, 32>
Dans le système UNIX, l’allocation est par bloc de taille fixe, ici 2 secteurs, soit 1024 octets. Dans notre configuration, cela veut dire 128 blocs par piste, et 512 blocs par cylindre. L’espace attribué au fichier est dont constitué :
La représentation de l’espace alloué au fichier est réparti en plusieurs niveaux, en utilisant au besoin des blocs contenant des numéros de blocs. En supposant les numéros de blocs sur 32 bits, ou 4 octets, un bloc peut contenir 256 numéros de blocs.
Les 10 premiers blocs du fichier sont conservés dans la table TABDIRECT du descripteur de fichier. Cette table contient donc dans l’ordre 16384, 16385,…, 16393.
Les 256 blocs suivants doivent être mémorisés dans un " bloc contenant des numéros de blocs ", et repéré par INDIRECT_1 dans le descripteur du fichier. Pour cela nous prendrons un bloc dans le cylindre 8, par exemple le premier, de numéro 4096 (8*512). Ce bloc contiendra :
Les blocs suivants doivent être mémorisés dans des " blocs contenant des numéros de blocs ", dont les numéros sont mémorisés dans un bloc repéré par INDIRECT_2 dans le descripteur du fichier. Pour cela nous prendrons d’abord un bloc dans le cylindre 8, par exemple le second, de numéro 4097 (8*512+1), pour contenir les numéros de blocs de données suivants :
Enfin, nous prendrons un dernier bloc dans le cylindre 8, par exemple le troisième de numéro 4098 (8*512+2), pour repérer le bloc précédent. Il contiendra donc 4097. Le numéro de ce bloc sera dans INDIRECT_2. Nous pouvons donc décrire l’ensemble par la figure suivante :
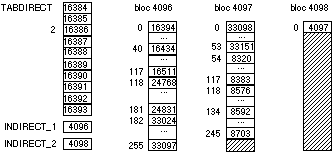
Pour accéder à un secteur logique de numéro ni du fichier, on commence par déterminer s’il est dans un bloc repéré par TABDIRECT, ou un des blocs INDIRECT. Selon les cas, on doit lire les blocs pointeurs de blocs jusqu’à trouver le numéro du bloc physique.
Pour le secteur 5, il s’agit du secteur 1 du bloc logique 2. Son numéro de bloc physique est obtenu dans l’entrée d’indice 2 de TABDIRECT. Il s’agit donc du bloc physique 16386. Il s’agit donc du secteur virtuel 2*16386+1=32773. Il s’agit donc du secteur relatif 32773 mod 1024=5 du cylindre 32773/1024=32, et donc du secteur 5 de la face 0 du cylindre 32. On a donc le triplet <32, 0, 5>.
Pour le secteur 100, il s’agit du secteur 0 du bloc logique 50. Le numéro de ce bloc est contenu dans le bloc INDIRECT_1 : il s’agit de l’entrée 40 (50-10) du bloc 4096, qui contient 16434. C’est donc le secteur virtuel 2*16434+0=32868. C’est donc cette fois le secteur 100 du cylindre 32, et donc le secteur 100 de la face 0 du cylindre 32, soit <32, 0, 100>
Pour le secteur 800, il s’agit du secteur 0 du bloc logique 400. C’est le bloc relatif 134 (400-10-256) de l’ensemble des blocs repérés depuis INDIRECT_2. Il faut donc lire le bloc 4098, puis le bloc 4097, et prendre l’entrée 134 de ce bloc, ce qui donne le bloc 8592. C’est donc le secteur virtuel 2*8592+0=17384. C’est donc le secteur relatif 17384 mod 1024=800 du cylindre 17384/1024=16, qui est le secteur 800 mod 256=32 de la piste située sur la face 800/256=3. On a donc le triplet <16, 3, 32>
Un processus peut se trouver dans différents états, suivant qu'il dispose de tout ou partie des ressources dont il a besoin pour s'exécuter. On distingue la ressource processeur de l'ensemble des autres ressources. En effet, s'il manque une ressource autre que le processeur, celui-ci ne peut faire évoluer le processus et il est donc inutile que cette ressource chère lui soit allouée. Lorsqu'il manque à un processus une ressource autre que le processeur, il est dans l'état bloqué. Lorsqu'un processus a toutes ses ressources à l'exception du processeur, il est dans l'état prêt. Enfin lorsqu'un processus a toutes ses ressources, y compris le processeur, il est dans l'état actif. L'allocation du processeur consiste à choisir un processus dans l'état prêt, et à lui allouer le processeur, le faisant passer dans l'état actif (transition 3). Un processus actif peut perdre le processeur, et repasser dans l'état prêt lorsque le système désire allouer le processeur à un autre processus (transition 2). Lorsqu'un processus actif demande une ressource qui n'est pas disponible, il passe dans l'état bloqué, et le processeur lui est retiré (transition 1). Lorsque la ressource demandée par un processus devient disponible, elle peut lui être allouée; le processus a alors toutes ses ressources sauf la ressource processeur et passe donc dans l'état prêt (transition 4).
Le processus est dans l'état bloqué lorsqu'il n'a pas toutes ses ressources, à l'exception de la ressource processeur. Pour passer dans cet état, il faut qu'il lui manque une ressource, soit parce qu'on la lui a retiré, ce qui n'est pas prévu ici, soit parce qu'il exprime un nouveau besoin, ce qui implique qu'il dispose du processeur pour exprimer ce besoin, c'est-à-dire qu'il soit actif. En conséquence, la seule transition vers l'état bloqué ne peut venir que de l'état actif. Par ailleurs, un processus quitte l'état bloqué lorsqu'il a toutes ses ressources pour s'exécuter, à l'exception de la ressource processeur, ce qui interdit la transition directe de bloqué à actif.
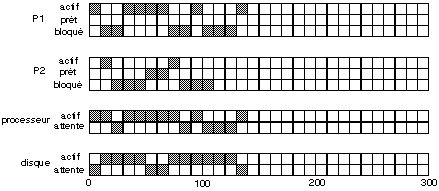
P1 est lancé à l’instant 0, il est donc prêt, et comme il est seul, il devient actif. Au temps 10 ms son opération disque, lecture de B1, est lancée, il passe donc dans l’état bloqué. En même temps, P2 est lancé, devient prêt et passe dans l’état actif.
Au temps 20, P2 demande un accès disque, lecture de B1, et passe donc en l’état bloqué. Mais, comme il y a déjà une opération disque en cours, cet accès ne peut commencer immédiatement. Aucun processus n’étant prêt, le processeur est inactif.
Au temps 30, la lecture de B1 pour P1 est terminée et P1 passe dans l’état prêt. La lecture de B1 pour P2 commence. P1 étant le seul processus prêt, il devient actif, pour 40 ms.
Au temps 50, la lecture de B1 pour P2 est terminée, et P2 passe dans l’état prêt. Étant mis en bout de file des processus prêts, il est derrière P1 qui reste actif.
Au temps 70, P1 demande l’écriture de B1, et passe donc dans l’état bloqué. P2 devient actif pour 10 ms.
Au temps 80, P2 demande l’écriture de B1, et passe dans l’état bloqué. Aucun processus n’est prêt, et le processeur est inactif.
Au temps 90, l’écriture de B1 pour P1 se termine, et P1 passe dans l’état prêt. L’écriture de B1 pour P2 commence. P1 étant le seul processus prêt, il devient actif, pour 10 ms.
Au temps 100, P1 demande la lecture de B2 et passe dans l’état bloqué. Comme le disque est occupé, la lecture ne commence pas.
Au temps 110, l’écriture de B1 pour P2 se termine, et P2 passe dans l’état prêt. La lecture de B2 pour P1 commence. P2 ayant terminé son travail sort du système.
Au temps 130, la lecture de B2 pour P2 se termine, et P1 passe dans l’état prêt, puis actif.
Au temps 140, P1 a terminé son travail et sort du système.
Le bloc B1 est écrit successivement par chacun des processus, après un certain traitement, qui fait suite à la lecture du même bloc B1. On peut penser que l’écriture dépend à la fois du traitement effectué et de la valeur du bloc B1 antérieur à ce traitement. Or une seule de ces écritures, la dernière et donc celle de P2 est conservée, la première est perdue puisque P2 travaille sur la version de B1 avant le traitement par P1 et non sur la version modifiée par P1.
Pour résoudre ce problème, il faut synchroniser les deux processus au moyen, par exemple, d’une exclusion mutuelle d’accès à leur séquence lecture-traitement-écriture. Nous utiliserons un mécanisme de verrou, et modifions les actions des processus comme suit :
|
Processus P1 calcul 10 ms |
Processus P2 calcul 10 ms |
P1 est lancé à l’instant 0, il est donc prêt, et comme il est seul, il devient actif. Au temps 10 ms, il demande le verrou et l’obtient. Puis il demande la lecture de B1, il passe donc dans l’état bloqué et la lecture est lancée. En même temps, P2 est lancé, devient prêt et passe dans l’état actif.
Au temps 20, P2 demande le verrou. Comme il n’est pas libre, P2 passe dans l’état bloqué. Le processeur est inactif.
Au temps 30, la lecture de B1 pour P1 est terminée et P1 passe dans l’état prêt. P1 étant le seul processus prêt, il devient actif, pour 40 ms.
Au temps 70, P1 demande l’écriture de B1, et passe donc dans l’état bloqué. Cette écriture est lancée. Le processeur est inactif.
Au temps 90, l’écriture de B1 pour P1 se termine, et P1 passe dans l’état prêt. P1 étant le seul processus prêt, il devient actif. À ce moment, il libère le verrou, permettant à P2 de devenir prêt, derrière P1 qui reste actif pour 10 ms.
Au temps 100, P1 demande la lecture de B2 et passe dans l’état bloqué. La lecture commence. P2 passe dans l’état actif, mais demande immédiatement la lecture de B1. P2 passe dans l’état bloqué, mais la lecture qu’il demande ne peut commencer.
Au temps 120, la lecture de B2 pour P2 se termine, et P1 passe dans l’état prêt, puis actif. En même temps, la lecture de B1 pour P2 commence.
Au temps 130, P1 a terminé son travail et sort du système. Le processeur est inactif.
Au temps 140, la lecture de B1 pour P2 est terminée, et P2 passe dans l’état prêt. Étant seul processus prêt, il devient actif pour 10 ms.
Au temps 150, P2 demande l’écriture de B1, et passe dans l’état bloqué. Aucun processus n’est prêt, et le processeur est inactif.
Au temps 170, l’écriture de B1 pour P2 se termine, et P2 passe dans l’état prêt. Il libère le verrou, puis ayant terminé son travail sort du système.