La construction de programmes peut devenir relativement complexe lorsque la taille du programme devient importante. Pour cela, on est amené à découper les programmes en modules. Chacun des modules peut être compilé de façon séparée. L'éditeur de liens a pour but de constituer un programme exécutable à partir d'un ensemble de modules. Le chargeur peut ensuite mettre en mémoire ce programme exécutable pour l'exécuter.
Le rôle de l'éditeur de liens se présente sous plusieurs aspects :
L'adresse d'implantation d'un module est 0 pour le premier, et pour les autres, le premier emplacement laissé libre par le module qui le précède, c'est-à-dire, la somme entre son adresse d'implantation et sa taille:
MACHIN 0
CHAINE 0 + 2800 = 2800
GETOPT 2800 + 1200 = 4000
SHADOK 4000 + 860 = 4860
UTIL 4860 + 1320 = 6180
taille totale 6180 + 530 = 6710
La taille totale du programme est la somme des tailles de tous les modules, ou encore l'adresse du premier emplacement laissé libre par le dernier module, c'est-à-dire, la somme entre son adresse d'implantation et sa taille, soit 6710.
La table des liens contient tous les identificateurs présents dans les modules, en tant que lien utilisable ou lien à satisfaire, ainsi que éventuellement les noms des modules (nous ne les mettrons pas ici). De plus, la table associe à tout identificateur rencontré comme lien utilisable dans un module, leur adresse dans le programme, obtenue en ajoutant à leur adresse dans ce module l'adresse d'implantation du module.
Après prise en compte du module TRUC
lu TRUC 0 + 400 = 400
lu EXIT_PROG 0 + 1200 = 1200
las GETOPT
las SCHMILBLIC
las ER_FATALE
Après prise en compte du module CHAINE
lu TRUC 0 + 400 = 400
lu EXIT_PROG 0 + 1200 = 1200
las GETOPT
las SCHMILBLIC
las ER_FATALE
lu SOUS_CHAINE 2800 + 150 = 2950
lu DEBUT 2800 + 352 = 3152
lu CONCATENER 2800 + 732 = 3532
Après prise en compte du module GETOPT
lu TRUC 0 + 400 = 400
lu EXIT_PROG 0 + 1200 = 1200
las GETOPT 4000 + 454 = 4454
las SCHMILBLIC
las ER_FATALE
lu SOUS_CHAINE 2800 + 150 = 2950
lu DEBUT 2800 + 352 = 3152
lu CONCATENER 2800 + 732 = 3532
Après prise en compte du module SHADOK
lu TRUC 0 + 400 = 400
lu EXIT_PROG 0 + 1200 = 1200
las GETOPT 4000 + 454 = 4454
las SCHMILBLIC 4860 + 1210 = 6070
las ER_FATALE
lu SOUS_CHAINE 2800 + 150 = 2950
lu DEBUT 2800 + 352 = 3152
lu CONCATENER 2800 + 732 = 3532
Après prise en compte du module UTIL
lu TRUC 0 + 400 = 400
lu EXIT_PROG 0 + 1200 = 1200
las GETOPT 4000 + 454 = 4454
las SCHMILBLIC 4860 + 1210 = 6070
las ER_FATALE 6180 + 413 = 6593
lu SOUS_CHAINE 2800 + 150 = 2950
lu DEBUT 2800 + 352 = 3152
lu CONCATENER 2800 + 732 = 3532
L'adresse de lancement est la valeur trouvée dans l'un des modules augmentée de l'adresse d'implantation de ce module: 0 + 1540 = 1540.
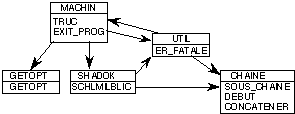
On a le graphe suivant des références entre les modules:
L'éditeur de liens parcours séquentiellement la bibliothèque pour savoir s'il doit ou non incorporer les modules successifs. Au cours de ce parcours, pour chaque module en bibliothèque, il regarde donc si ce module, par ses liens utilisables, peut satisfaire un lien de la table, encore non satisfait. Si c'est le cas, il ajoute le module à la liste, et effectue le traitement du premier passage sur ce module, c'est-à-dire, définit son implantation, et ajoute ses liens à la table. Si ce module contient un lien à satisfaire qui n'était pas encore dans la table, il doit pouvoir être satisfait par un module qui le suit dans la bibliothèque. Le graphe de la figure montre alors que l'on doit respecter les ordres suivants, entre les 4 modules CHAINE, GETOPT, SHADOK et UTIL:
SHADOK
précède UTIL
SHADOK précède CHAINE
UTIL
précède CHAINE
Les ordres possibles sont donc:
GETOPT SHADOK UTIL CHAINE
SHADOK GETOPT UTIL CHAINE
SHADOK UTIL GETOPT CHAINE
SHADOK UTIL CHAINE GETOPT
On note que MACHIN exporte le lien TRUC, et CHAINE exporte le lien SOUS_CHAINE, aucun des deux n'étant à satisfaire dans les autres modules. On sait que, puis que MACHIN contient une adresse de lancement, il s'agit d'un programme principal. Le fait qu'il exporte un lien sans qu'il soit à satisfaire dans un autre module est probablement une anomalie : à moins de modifications dans les modules, MACHIN ne sera jamais utilisé avec d'autres que ceux fournis. Par contre, CHAINE n'est pas un programme principal, et sa mise en bibliothèque dans la question C laisse penser qu'il peut être utilisé en tant que tel dans d'autres programmes, dans lesquels le lien exporté sera alors nécessaire.
Il s'agit de donner la suite des noms de répertoires, partant de la racine permettant d'atteindre le fichier correspondant. On a donc :
/usr/bin/gcc
/users/pierre/travail/tri.c
/users/pierre/bin/tri
La première méthode pour simplifier un chemin d’accès consiste souvent à partir du répertoire de travail plutôt que de la racine de l’arborescence. Par exemple, si dans la question précédente, le répertoire de travail est /users/pierre/travail, le deuxième chemin d'accès se résume à tri.c.
Les chemins d'accès peuvent également être simplifiés, dans certains contextes, par le biais des règles de recherche. Par exemple, si on définit une règle de recherche des programmes exécutables par une liste de répertoires contenant les répertoires /users/pierre/bin et /usr/bin, les premier et troisième chemins d'accès de la question précédente, dans le contexte de demande d’exécution de programme, deviennent simplement gcc et tri.
Lorsque le nombre de fichiers est important, le choix de leur désignation devient difficile, puisqu'il faut trouver des noms différents pour chacun. Il s'agit alors de partitionner l'ensemble des fichiers en petits sous ensembles, chaque sous ensemble étant attaché à un répertoire qui lui est propre. Le procédé peut être recommencé sur les sous ensembles, lorsque le nombre de ces sous ensembles est important. Ceci conduit à une arborescence de répertoires et de fichiers. Un répertoire est une table qui associe un nom et un descripteur d'objet, celui-ci pouvant être un fichier ou un autre répertoire.
On peut profiter de ce partitionnement pour regrouper ensemble des fichiers qui ont des relations entre eux. Ainsi, dans notre exemple, les exécutables courants sont regroupés dans le répertoire /bin. Les exécutables d'applications courantes sont regroupés dans /usr/bin, et les fichiers de l'utilisateur Pierre sont regroupés dans une sous arborescence /users/pierre.
Selon l'algorithme LRU, le choix est la page la moins récemment référencée. Comme la date du dernier référencement à la page est donnée par la colonne "Accès", il s'agit donc de trouver celle qui a la date la plus ancienne, c'est-à-dire la case 2 dans notre cas, référencée en 820.
Selon l'algorithme FIFO, le choix est la page la plus ancienne en mémoire. Comme la date de chargement des pages en mémoire est donnée par la colonne "Chargt", il s'agit de trouver la plus ancienne dans cette colonne, c'est-à-dire la case 0 dans notre cas, amenée en mémoire en 100.
L'algorithme de la seconde chance, dérive de l'algorithme FIFO: on donne une seconde chance à la page la plus ancienne si elle a été accédée dans un passé récent (marque "accédée" à 1). Dans notre cas, la case 100 a effectivement le bit "accédée" à 1, on remet donc ce bit à 0 après avoir remis la case en tête de file. La suivante est la case 1. Comme son bit "accédée" est à 0, c'est elle qui est choisie.
Dans l'algorithme NRU, on classe les cases dans des catégories selon les trois bits "accédée", "modifiée" et "présence". Dans notre exemple, les cases 0 et 3 sont dans la catégorie 1, la case 1 est dans la catégorie 3 et la case 2 est dans la catégorie 4. On prend une case dans la catégorie de numéro le plus élevée c'est-à-dire ici dans la catégorie 4. C'est donc la case 2 qui est choisie.