12
La gestion des processus
Nous avons vu dans les premiers chapitres que l'introduction
des activités parallèles avait permis d'améliorer la
rentabilité des machines. Le parallélisme peut être
lié à des activités spécifiques, et donc obtenu par
des processeurs spécialisés. Par exemple, un transfert
d'entrées-sorties peut être exécuté en même
temps qu'un calcul interne au processeur. Il peut aussi être le moyen
d'obtenir plus de puissance de calcul dans le même temps imparti, en
utilisant plusieurs processeurs de calcul.
Plus généralement, un processeur peut
exécuter une séquence d'instructions d'un programme, puis ensuite
une séquence d'instructions d'un autre programme, avant de revenir au
premier, et ainsi de suite. Si la durée d'exécution des
séquences est assez petite, les utilisateurs auront l'impression que les
deux programmes s'exécutent en parallèle. On parle alors de
pseudo-parallélisme. Évidemment, vu du processeur
lui-même, il s'agit d'une activité unique et séquentielle,
un programme de supervision décidant de la séquence à
exécuter. C'est ce programme de supervision, inclus dans le
système, qui donne en fait l'illusion du parallélisme. Si la
recherche de la meilleure efficacité du matériel a
été à l'origine du parallélisme et reste un aspect
important, le pseudo-parallélisme permet à plusieurs utilisateurs
d'utiliser une même machine au même instant, et à chacun
d'eux de lancer plusieurs activités en même temps, comme par
exemple compiler un module source pendant que l'on modifie un autre module
source. La gestion de ces activités parallèles est en
général assez complexe, et difficile à appréhender.
Le concept de processus est fondamental pour la compréhension de cette
gestion, tant pour le concepteur de système que pour
l'utilisateur.
12.1. La notion de processus
Le terme de programme est souvent utilisé
à des sens différents. Lorsqu'il est utilisé pour
désigner l'ensemble des modules sources, l'ensemble des modules objets ou
le résultat de l'édition de liens, il représente toujours
la même abstraction, écrite dans différents langages de
représentation, de la description des actions à
entreprendre pour aboutir au résultat recherché. Cet aspect
description des actions est en fait fondamental, et le terme de programme ne
devrait être utilisé que dans ce sens.
Le terme de processeur est utilisé pour
désigner l'entité (matérielle ou logicielle) qui est
capable d'exécuter des instructions. Jusqu'à maintenant, nous
l'avons utilisé essentiellement pour désigner une entité
matérielle, comme le processeur de calcul, ou le processeur
d'entrées-sorties, et nous continuerons à l'utiliser dans ce sens,
mais il peut parfois être intéressant de considérer qu'un
interpréteur, par exemple, est un processeur logiciel capable
d'exécuter des instructions du langage qu'il interprète.
La notion de processus a été introduite
pour désigner l'entité dynamique qui correspond à
l'exécution d'une suite d'instructions. C'est un concept abstrait, en ce
sens qu'il désigne l'évolution d'une activité dans le
temps. C'est le processeur qui fait évoluer cette activité en
exécutant les instructions définies par un programme. Le
système doit permettre de distinguer les différents processus qui
existent à un instant donné, et doit représenter leur
état. Celui-ci permet, d'abord, de localiser le programme lui-même,
c'est-à-dire la suite d'instructions, ensuite, de déterminer les
données propres et les variables, enfin de représenter
l'état du processeur après l'exécution d'une instruction
quelconque du programme (registres, compteur ordinal, mot d'état
programme,...).
Pour bien montrer la différence entre programme et
processus, nous reprendrons une image de Tanenbaum. Supposez qu'un informaticien
décide de faire un gâteau pour l'anniversaire de sa fille. Pour
être certain de le réussir, il ouvre devant lui son livre de
recettes de cuisine à la page voulue. La recette lui précise les
denrées dont il a besoin, ainsi que les instruments nécessaires.
À ce stade, nous pouvons comparer la recette sur le livre de cuisine au
programme, et l'informaticien au processeur. Les denrées sont les
données d'entrées, le gâteau est la donnée de sortie,
et les instruments sont les ressources nécessaires. Le processus est
l'activité dynamique qui transforme les denrées en
gâteau.
Supposez que, sur ces entrefaites, le fils de l'informaticien
vient se plaindre qu'il a été piqué par une abeille.
L'informaticien interrompt son travail, enregistre l'endroit où il en
est, extrait de sa bibliothèque le livre de première urgence, et
localise la description des soins à apporter dans ce cas. Lorsque ces
soins sont donnés et que son fils est calmé, l'informaticien
retourne à sa cuisine pour poursuivre l'exécution de sa
recette.
On constate qu'il y a en fait deux processus distincts, avec
deux programmes différents. Le processeur a partagé son temps
entre les deux processus, mais ces deux processus sont
indépendants.
Supposez maintenant que la fille de l'informaticien vienne lui
annoncer de nouveaux invités. Devant le nombre, l'informaticien
décide de faire un deuxième gâteau d'anniversaire identique
au premier. Il va devoir partager son temps entre deux processus distincts qui
correspondent néanmoins à la même recette,
c'est-à-dire au même programme. Il est évidemment
très important que le processeur considère qu'il y a deux
processus indépendants, qui ont leur propre état, même si le
programme est le même.
De même que l'informaticien aura un seul exemplaire de
la recette pour les deux processus, de même dans une situation analogue en
machine, le programme lui-même pourra se trouver en un seul exemplaire en
mémoire, pourvu que d'une part le code ne se modifie pas lui-même,
d'autre part qu'il permette d'accéder à des zones de
données différentes suivant que les instructions sont
exécutées pour le compte de l'un ou l'autre des processus. On dit
alors que le programme est réentrant.
L'indépendance entre les processus conduit parfois
à introduire la notion de processeur virtuel. Chaque processus se
voit attribuer un tel processeur virtuel qu'il possède en propre, et qui
exécute les instructions du programme pour le compte du processus. Le
système implante ces processeurs virtuels en attribuant le (ou les)
processeur réel alternativement aux différents processeurs
virtuels. Chaque processus avance au rythme de son processeur virtuel, induisant
un temps virtuel, qui correspond au temps d'utilisation du processeur
virtuel. Il correspond aussi à la fraction du temps réel pendant
laquelle un processeur réel a été attribué au
processeur virtuel. En conséquence un temps virtuel de 1 seconde
correspond à l'exécution d'un certain nombre d'instructions par le
processeur réel, que ces instructions aient été
réalisées en une seule fois, ou en plusieurs tranches de
temps.
12.2. La hiérarchie de processus
Nous avons dit que la représentation d'un processus
comportait trois composantes principales, le programme, les variables et
l'état du processeur.
12.2.1. Un nombre fixe de processus banalisés
Certains systèmes créent, à
l'initialisation, un nombre fixe de processus banalisés.
Ces processus peuvent être attachés chacun
à un terminal particulier. Le programme du processus consiste alors en
l'identification de l'usager (login) suivi de l'exécution de ses
commandes et se termine par la remise dans l'état initial lors de la
déconnexion (logout).
Ces processus peuvent être attachés à un
terminal au moment de la demande de connexion depuis de terminal. Le programme
est alors comparable au précédent. Le nombre de processus peut
être inférieur au nombre de terminaux potentiels, entraînant
un refus de connexion si aucun processus n'est disponible. Il est
également possible d'allouer le processus à un couple de fichiers
<entrée, sortie>, qui simulent le comportement d'un usager à
son terminal, ce qui fournit une certaine forme de traitement par lot.
Ces processus peuvent être alloués à la
demande pour une exécution d'une commande unique. Le programme, qui
décrit leur comportement, est une boucle infinie qui consiste en
l'attente d'une commande, suivie de son exécution. Suivant le cas,
plusieurs processus pourront être alloués à un même
usager en fonction de ses besoins. Cependant, il est nécessaire de
disposer de plus de processus que dans les cas précédents, et la
représentation de la partie propre de leur état occupe de la place
en mémoire.
12.2.2. La création dynamique de processus
La création statique de processus banalisés
présente l'inconvénient d'occuper de la place en mémoire,
même lorsqu'ils ne sont pas utilisés. La deuxième
méthode consiste à fournir une opération de création
dynamique de processus ainsi qu'une opération de destruction de ces
processus. Un telle opération de création doit permettre
d'initialiser l'état du nouveau processus. Elle doit donc définir
d'une part le programme (ou la suite d'instructions) décrivant
l'activité du processus, ainsi que l'état initial de ses
données, de ses variables et des registres du processeur. Elle doit donc
se présenter sous la forme suivante:
id := créer_processus (programme, contexte)
où
les paramètres définissent cet état initial. La valeur
retournée éventuellement par cette opération permet
d'identifier le processus qui a été ainsi créé.
Cette dernière valeur n'a d'intérêt que si le processus
créateur peut agir ultérieurement sur le processus
créé au moyen d'autres opérations.
La plupart des systèmes qui permettent la
création dynamique de processus considèrent que la relation entre
le processus créateur et le processus créé est importante,
ce qui conduit à structurer l'ensemble des processus sous la forme d'un
arbre, et à maintenir cette structure. Lors de la création de
processus, le processus créé est relié automatiquement
comme fils du processus créateur. Si un processus est détruit, on
peut parcourir sa descendance pour la détruire au préalable. Lors
de la fin d'exécution normale d'un processus P, deux solutions
sont possibles:
- La destruction de P n'est effective que
lorsque tous ses fils sont eux-mêmes achevés. Ceci est
nécessaire lorsque le contexte initial du fils est inclus dans le
contexte de P, puisque la destruction de celui-ci entraînerait la
perte d'une partie du contexte du fils, et donc un déroulement anormal du
processus fils s'il pouvait exister après la destruction de son
père.
- La destruction de P
entraîne le rattachement de ses fils à l'un de ses ancêtres.
Cependant comme l'ascendance du processus P n'a pas de connaissance de ce
qu'a fait P, on rattache souvent les fils soit au processus qui a
initialisé le travail (login), soit à la racine qui est un
processus standard et
éternel.
12.2.3. L'exemple de Unix
Dans le système Unix, la création dynamique de
processus est simplifiée à l'extrême, puisqu'il s'agit de
créer un processus qui est une exacte copie de celui qui demande la
création. Aucun paramètre n'est donc nécessaire, puisque le
programme est le même, et que le système réalise une copie
des données, variables et registres du processus demandeur pour
créer le nouveau processus. La seule distinction entre le processus
créateur et le processus créé, réside dans la valeur
retournée par la fonction de création. Le processus
créateur reçoit l'identité du processus créé,
alors que ce dernier reçoit la valeur 0. Par ailleurs, le système
structure les processus en arbre. Considérons le petit morceau de
programme suivant:
id_fils := fork (); { création du fils }
si id_fils = 0 alors { il s'agit du processus fils }
sinon { il s'agit du processus père }La
fonction fork () crée le processus
fils comme copie conforme du processus père. Les deux processus repartent
donc après l'appel de la fonction, avec le même programme, et leur
propres zones de données et de variables identiques à ce moment.
La mémorisation du résultat dans la variable
id_fils signifie la mémorisation
dans un emplacement mémoire propre à chacun d'eux. Notons que,
puisque le fils obtient une copie des données du père, celui-ci
peut lui transmettre tout ce qu'il désire à ce moment. Par la
suite, les deux processus sont effectivement indépendants et n'ont pas de
données communes à l'exception des objets externes.
Si le processus père se termine avant le processus
fils, le fils est rattaché au processus racine de façon à
conserver la structure d'arbre. Le processus père peut attendre la
terminaison d'un de ses fils par la fonction (en langage C):
id_fils := wait (&status);
qui
retourne le numéro d'un processus fils qui est terminé, en mettant
dans la variable status un code indiquant
la façon dont ce processsus s'est terminé. Si aucun fils n'est
terminé alors qu'il y en a encore d'actifs, le processus père est
mis en attente d'une terminaison de l'un de ses fils. S'il n'y a plus de
processus fils, la fonction retourne la valeur
-1.
Par ailleurs le système Unix fournit une fonction
exec qui permet à un processus de
changer le programme en cours d'exécution. Cette fonction n'affecte
évidemment que le processus demandeur. Elle change l'état du
processus en remplaçant le code des instructions, en supprimant les
données, variables et registres qui étaient relatifs à
l'ancien programme et en les initialisant pour le nouveau. La combinaison de la
fonction fork et de cette fonction
exec par le processus fils permet de
réaliser la fonction
créer_processus mentionnée
ci-dessus.
12.3. La notion de ressources
Si nous reprenons notre exemple du processus de
réalisation du gâteau d'anniversaire, ce processus ne peut
s'exécuter que si les denrées nécessaires pour la recette
sont disponibles, ainsi que les ustensiles de cuisines correspondants. Ce sont
des ressources dont a besoin ce processus. Si on désire faire un
deuxième gâteau identique, un deuxième processus doit
être créé pour le réaliser. Cet autre processus aura
besoin également de ressources, et peut alors être en conflit avec
le premier processus s'il n'y a pas assez de certaines ressources. Par exemple,
si la cuisson doit être faite au four, il est possible que le four soit
assez grand pour admettre les deux gâteaux en même temps. Le batteur
ne pourra pas par contre être utilisé en même temps par les
deux processus. Le processeur étant unique (l'informaticien) ne pourra
pas commencer de battre la pâte pour le compte de l'un des processus, si
l'autre possède la ressource batteur et ne l'a pas restituée
(lavé et essuyé les embouts). Par contre, l'horloge peut
être partagée par tous les processus éventuels
gérés par l'informaticien.
On appelle ressource toute entité dont a besoin
un processus pour s'exécuter. Il en est ainsi du processeur physique, de
la mémoire, des périphériques. Il en est également
ainsi des données dont a besoin le processus et qui seraient
momentanément indisponibles. Il en est enfin ainsi de
l'événement de fin d'exécution d'un processus Unix pour le
processus père qui l'attend. Pour chaque ressource, une
caractéristique importante est le nombre de processus qui peuvent
utiliser la ressource au même moment.
- Il peut y en avoir un nombre quelconque. Il n'y
a alors pas de contrôle à mettre en œuvre. Dans l'exemple
culinaire, l'horloge a été considérée comme une
ressource qui peut être accédée par un nombre quelconque de
processus.
- Il peut y en avoir plusieurs, mais en
nombre limité. Il faut alors contrôler lors des allocations que ce
nombre n'est pas dépassé. Dans l'exemple culinaire, le four ne
peut être utilisé simultanément que par deux
processus.
- Il peut y avoir au plus un processus
qui utilise la ressource. Dans l'exemple culinaire, le batteur ne peut
être utilisé que par au plus un processus. On dit alors que la
ressource est une ressource critique. On dit aussi que les processus sont
en exclusion mutuelle pour l'accès à cette ressource. Il en
est ainsi du processeur physique, d'une imprimante, d'un dérouleur de
bande, etc...
Pour les ressources physiques critiques,
nous avons déjà proposé une première solution pour
le processeur, qui peut être généralisée dans
certains cas, en remplaçant une telle ressource physique par une
ressource virtuelle. Dans ce cas, le système met en œuvre des
mécanismes de coopération entre les processus, qui sont
cachés dans le système et donc invisibles des processus
eux-mêmes, pour leur permettre de “faire comme si” ils avaient
la ressource pour eux seuls. On peut ainsi simuler un nombre quelconque
d'imprimantes virtuelles sous forme de fichiers sur disque dont les impressions
sont réalisées successivement par le système sur une
même imprimante physique.
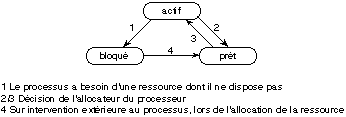
12.4. Les états d'un processus
Lorsqu'un processus n'a pas toutes les ressources dont il a
besoin pour s'exécuter, il est nécessaire de le bloquer en
attendant que ces ressources soient disponibles. La figure 12.1 montre les
différents états que peut prendre un processus, lorsqu'il existe.
Lors de la création il est mis, en général, dans
l'état bloqué, en attendant qu'il ait toutes les ressources dont
il a besoin initialement. Sa destruction peut subvenir dans n'importe quel
état à la suite d'une décision interne s'il est actif, ou
externe s'il est dans un autre état. Dans ce cas, il faut
récupérer toutes les ressources qu'il possédait.
Fig. 12.1. Les principaux états d'un
processus.
Il est assez naturel de considérer de façon
particulière la ressource processeur physique. Pour le moment c'est
encore une ressource chère, qu'il vaut mieux ne pas gaspiller. Par
ailleurs il est inutile de la donner à un processus à qui il
manque une autre ressource, puisque ce processus ne peut alors évoluer:
le processeur ne pourrait que constater ce manque et attendre la
disponibilité de cette ressource (c'est ce que l'on appelle l'attente
active). C'est pourquoi on distingue trois états:
- l'état actif où le
processus dispose de toutes les ressources dont il a
besoin,
- l'état bloqué
où le processus a besoin d'au moins une ressource autre que le processeur
physique,
- l'état prêt
où le processus dispose de toutes les ressources à l'exception du
processeur physique.
La transition 1 survient lorsque, le
processus étant actif, il exprime le besoin de disposer d'une nouvelle
ressource. Cette expression peut être explicite, sous forme d'une demande
au système, ou implicite, sous forme d'un accès à cette
ressource non allouée. Le processus doit évidemment disposer du
processeur pour pouvoir exprimer ce besoin. Il peut se faire que la transition
vers l'état bloqué par manque de ressources, entraîne que le
système lui retire d'autres ressources qu'il possédait, en plus de
la ressource processeur physique, comme par exemple de la mémoire
centrale. En général, on ne lui retire que des ressources
chères, qu'il est relativement facile et peu coûteux de lui
restituer ultérieurement, dans l'état où elles
étaient au moment où on les lui a enlevées. Il est assez
naturel de considérer de façon particulière la ressource
processeur physique. L'état bloqué correspond alors au manque
d'une ressource autre que le processeur physique, et l'état prêt
correspond alors au manque de la seule ressource processeur.
La transition 4 est la conséquence d'un
événement extérieur au processus. Celui-ci était
bloqué en attente d'une ou plusieurs ressources. Lorsque le
système constate qu'il a pu lui allouer toutes les ressources (autres que
le processeur) dont il a besoin, il le fait passer dans l'état
prêt. La disponibilité de la ressource attendue se présente,
en général, sous l'une des deux formes suivantes:
- C'est le résultat d'une action par un
autre processus. Il peut s'agir de la libération de la ressource, ou de
la création de la ressource elle-même. Ainsi la fin
d'exécution d'un processus crée la ressource
événement attendue par son
père.
- C'est le résultat d'une
action extérieure. Il peut s'agir d'une interruption en provenance d'un
périphérique, par exemple, ou d'un événement
déclenché par l'opérateur ou un
utilisateur.
Les transitions 2 et 3 sont sous la
responsabilité de la partie du système qui alloue le processeur
physique. C'est à ce niveau que s'implante la notion de processeur
virtuel dont nous avons déjà parlé. Certains
systèmes n'implantent pas la transition 2. Il s'ensuit que lorsqu'un
processus est actif, il le reste jusqu'à ce qu'il soit terminé ou
qu'il ait besoin d'une ressource qu'il n'a pas. L'allocation du processeur
consiste alors à choisir un processus parmi les processus prêts, et
à le faire passer dans l'état actif. Cela peut entraîner que
les processus prêts peuvent attendre très longtemps pour devenir
actif, si le choix a conduit à rendre actif un processus qui calcule sans
exprimer le besoin de nouvelles ressources. Ceci peut être
évité par le biais de la transition 2 qui doit être la
conséquence d'une action extérieure au processus actif. C'est en
général un des rôles attribués à
l'interruption d'horloge de déclencher cette transition.
Il est important de noter que ces transitions ne sont pas
instantanées, puisqu'il s'agit de ranger en mémoire l'état
du processeur relatif à l'ancien processus actif, et de restituer
l'état du processeur avec celui relatif au nouveau processus actif, une
fois le choix de celui-ci effectué. L'exécution de ces transitions
consomme du temps de processeur physique, qui n'est pas utilisé par les
processus eux-mêmes. C'est ce que l'on appelle la
déperdition (overhead) résultant de la gestion des
processus. Tous les systèmes visent à réduire cette
déperdition dans des limites raisonnables. C'est le prix à payer
pour une meilleure fonctionnalité.
12.5. Conclusion
+ Un processus est
l'entité dynamique qui correspond à l'exécution d'une suite
d'instructions définie par le programme. Le processeur est
l'entité qui exécute les instructions pour le compte du
processus.
+ Lorsqu'un processus
n'a pas le processeur, il ne peut évoluer, et son état doit
être conservé en mémoire. Lorsqu'il a le processeur, son
état évolue, et est représenté en partie par les
registres du processeur.
+ Il peut y avoir un
nombre fixe de processus dans un système, ou bien les processus peuvent
être créés dynamiquement. Dans ce cas, l'ensemble des
processus est structuré en arborescence suivant la relation
créateur-créé.
+ La création
d'un processus doit définir le programme qu'il doit exécuter, et
le contexte initial de cette exécution. Sur Unix, le processus
créé est une copie conforme du processus
créateur.
+ Une ressource est
une entité dont a besoin un processus à un instant donné
pour s'exécuter. Elle est caractérisée, en particulier, par
le nombre de processus qui peuvent l'utiliser au même moment. Ce nombre
peut être illimité, et aucun contrôle n'est nécessaire
lors de l'allocation.
+ Si le nombre de
processus pouvant utiliser une ressource est borné, il faut
contrôler lors de l'allocation que la borne n'est pas atteinte. Lorsque
cette borne est égale à 1, on dit que la ressource est critique,
et que les processus sont en exclusion mutuelle pour cette ressource.
+ Les ressources
induisent trois états sur les processus: l'état actif lorsque le
processus a toutes ses ressources, l'état prêt lorsque le processus
a toutes ses ressources sauf le processeur et l'état bloqué
lorsqu'il lui manque des ressources autres que le processeur.
+ Le passage de
l'état actif à l'état bloqué est en
général volontaire, ou à la suite d'une réquisition.
Le passage de l'état bloqué à l'état prêt est
dû à une action externe au processus.