11
Quelques exemples de SGF
Pour terminer cette partie, nous allons présenter
brièvement quelques systèmes de gestion de fichiers (SGF), dont
nous avons déjà abordés certains aspects à titre
d'exemple particuliers. Nous décrirons surtout la structure, sans entrer
dans le détail des algorithmes utilisés par les systèmes,
et qui peuvent évoluer d'une version à l'autre.
11.1. Les systèmes FAT et VFAT
VFAT est une extension de FAT dont nous avons
déjà parlé. Ces SGF sont capables de gérer des
partitions dont la taille est limitée à 2 Go. Cet espace est
constitué de 3 parties:
- la FAT proprement dite, éventuellement
dupliquée,
- le répertoire racine du
volume,
- les données des objets externes du
volume.
11.1.1. Représentation de l'espace
L'allocation d'espace se fait par bloc de taille fixe,
appelés cluster, qui est constitué d'un nombre entier de
secteurs (au plus 255). Les clusters ont un numéro sur 16 bits (au plus
65 535). La FAT a un double rôle:
- déterminer les clusters occupés,
ceux qui sont libres et ceux qui sont invalides et pour lesquels il y a eu des
erreurs de lecture auparavant,
- déterminer
pour chaque cluster alloué à un objet externe quel est le cluster
suivant de cet objet.
L'allocation d'espace se fait bloc
par bloc, par un parcours séquentiel de la FAT. Lors d'un parcours
séquentiel d'un fichier logique, le système suivra la liste
chaînée des clusters. Lors d'un accès aléatoire, il
devra également effectuer ce parcours depuis le début de l'objet
externe jusqu'au cluster recherché.
11.1.2. Les répertoires
Ce système utilise une arborescence de
répertoires, la racine de cette arborescence étant située
derrière la FAT. Notons que cette racine peut contenir 512
entrées, alors que les autres répertoires peuvent en contenir un
nombre quelconque. Une entrée d'un répertoire contient 32 octets
et est constituée comme suit:
- Le nom du fichier sous la forme dite "8.3",
c'est-à-dire, 8 caractères avant le point et 3 après. Ces
noms doivent commencer par une lettre et sont insensibles à la casse (pas
de différenciation entre les majuscules et les minuscules).
- Un ensemble d'attributs précisant, entre
autre, la nature de l'objet externe (fichier ou répertoire) et sa
protection (écriture autorisée).
- L'heure et la date de dernière
modification de l'objet externe.
- Le numéro
du premier cluster de l'objet externe.
- La
longueur utile en octet de l'objet externe sur 32
bits.
- De plus,10 octets sont
inutilisés.
Un répertoire contient toujours
deux entrées particulières: "." qui désigne le
répertoire lui-même et ".." qui désigne le répertoire
parent.
Notons ici une extension apportée par le système
VFAT, pour permettre les noms longs. Lors de la création d'un nom de
fichier, qui peut être sur 255 caractères, le système
crée en fait 2 noms: l'un est le nom origine, l'autre est un alias sous
la forme DOS 8.3 construit à partir du nom long. Le nom DOS occupe une
entrée du répertoire, et les entrées suivantes contiennent
les tranches successives de 13 caractères du nom long. Un tel nom long
peut donc occuper jusqu'à 21 entrées! Comme le répertoire
racine est limité à 512 entrées, ceci a pour
conséquence de limiter à 24 objets externes ce répertoire
si on utilise des noms de 255 caractères à ce niveau.
Notons que si le système FAT (et VFAT) a
été créé par Microsoft pour le DOS, il est
maintenant compatible avec un grand nombre de systèmes. Par ailleurs, on
peut noter qu'il permet une assez bonne occupation de l'espace et devrait donc
être réservé à de petites partitions.
11.2. Les systèmes HFS et HFS Plus de MacOS
Le système HFS Plus est une nouvelle version de SGF,
introduite par Apple pour pallier certaines limites de HFS, tout en reprenant
les mêmes concepts. Nous allons décrire HFS, et montrerons les
évolutions. Une partition HFS (Hierarchical File System) est
constituée de 6 parties:
- Les informations de démarrage du
système permettent, par exemple, de localiser le système dans la
partition, ou de connaître la taille des tampons internes, etc. Cette
partie contient des zéros si la partition n'est pas une partition de
démarrage.
- Le descripteur du volume. On
y trouve, en particulier, le nom du volume (limité à 27
caractères), ainsi que des informations diverses sur la structure du
volume.
- La table bitmap décrivant
l'état d'allocation du volume.
- Le
catalogue des fichiers et
répertoires.
- Le fichier de description
des extensions.
- Les espace des objets externes
du volume.
Les objets externes (fichiers et
répertoires) créés sur le volume reçoivent un
numéro interne unique d'identification que nous appèlerons Num-ID.
Ce numéro est défini à la création du fichier ou du
répertoire.
11.2.1. La représentation de l'espace.
HFS utilise le principe de l'allocation par zone, un objet
externe pouvant avoir un nombre quelconque de zones chacune étant de
taille quelconque (cf. 8.2.3). La taille du quantum est un nombre entier de
secteurs. Nous utiliserons le terme de bloc pour désigner les
unités d'allocation. Les blocs sont numérotés sur 16 bits,
limitant à 65536 le nombre de ces blocs. Ceci a deux
conséquences:
- La table bitmap évoquée
ci-dessus est de taille fixe d'au plus 8 Ko.
- La taille d'un quantum est égal au
moins à la taille de la partition divisée par 65536, soit
64 Ko pour une partition de 4 Go.
Nous verrons
ci-dessous que les répertoires n'ont pas d'espace qui leur soit
alloué en propre. Par contre, tout fichier contient deux parties
distinctes: la partie ressource et la partie données, chacune d'elles
étant limitée en taille à 2 Go. Cette
séparation est souvent utilisée par les applications pour isoler
la partie présentation de la partie contenu. Ce qui nous importe ici est
que chacune possède son propre espace alloué. Notons que, en
général, la partie ressource est assez petite, mais, si elle n'est
pas vide, elle occupe au moins un bloc.
Le descripteur de fichier contient la description des trois
premières zones allouées à chacune des parties du fichier,
chaque zone étant décrite par le numéro du premier bloc et
le nombre de blocs. Si une partie a besoin de plus de trois zones, les
descriptions des zones manquantes sont regroupées, par groupe de 3, dans
le fichier de description des extensions vu plus haut.
Chaque entrée de ce fichier est constituée des
champs suivants, les trois premiers composant la clé d'identification de
l'entrée:
- Num-ID du
fichier.
- Indicateur précisant si on a
affaire à la partie ressource ou à la partie
données.
- Numéro logique à
l'intérieur du fichier correspondant à la première zone. Ce
numéro est en fait égal à la somme des longueurs des zones
allouées qui précèdent la première du
groupe.
- Description des trois zones
allouées.
Pour faciliter les accès, les
entrées sont organisées en arbre B*. Nous n'entrerons pas ici dans
le détail d'une telle structure, mais nous suggérons le lecteur de
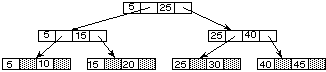
voir un cours de structures de données. Brièvement, la figure 11.1
donne un exemple simple d'arbre B*, où les clés sont simplement
des entiers. Dans notre cas, chaque nœud occupe un secteur.
Fig. 11.1. Exemple d'arbre B*
utilisé dans HFS.
Notons que si un fichier est fragmenté, et occupe plus
de 3 zones, le système devra rechercher dans l'arbre le ou les groupes de
3 zones nécessaires. Cependant, les entrées correspondantes sont
en fait ordonnées dans le fichier de description des extensions,
puisqu'il s'agit d'un arbre B*.
Le fichier de description des extensions est également
utilisé pour conserver les blocs invalides, c'est-à-dire ceux pour
lesquels on a détecté une erreur permanente. Ces blocs sont
affectés, comme zone d'extension, à un objet externe de Num-ID
particulier qui n'est repéré par aucun répertoire. Ainsi,
ces blocs sont considérés comme alloués, mais l'objet
auquel ils sont alloués n'est pas accessible.
11.2.2. Les répertoires
Ce système utilise une arborescence de
répertoires, mais avec une représentation originale de cette
arborescence, puisque l'ensemble est également représenté
dans un arbre B* unique, que nous avons appelé ci-dessus le catalogue des
fichiers et répertoires. À chaque objet externe, on associe une
entrée de ce catalogue qui est constituée essentiellement des
champs suivants, les deux premiers composant la clé d'identification de
l'entrée:
- Num-ID de son répertoire
parent.
- Nom de l'objet externe, limité
à 31 caractères quelconque à l'exception du ':', la casse
n'intervenant pas dans les comparaisons.
- Le
type de l'entrée, et donc de l'objet externe, fichier ou
catalogue.
- Dates de création,
modification et sauvegarde.
- Num-ID de l'objet
lui-même.
- Descripteur de fichier dans le
cas d'un fichier. En particulier, pour chacune des parties du fichier, la taille
physique (allouée), sa taille logique (utile) et les descripteurs des
trois premières zones allouées à cette
partie.
Par ailleurs, le catalogue contient des
entrées spéciales qui permettent de remonter dans l'arborescence
depuis un répertoire à son parent, et que nous appellerons un
lien. Une telle entrée est constituée comme suit, les deux
premiers champs étant toujours la clé de
l'entrée:
- Num-ID du répertoire
- "", ou chaîne
vide.
- Le type de l'entrée en tant que
lien.
- Num-ID de son
parent.
- Nom du répertoire
lui-même.
Par ailleurs, le catalogue, en tant que
arbre B*, a toutes ses entrées ordonnées par clés
croissantes. Par conséquent, le lien d'un répertoire vers son
parent est immédiatement suivi des entrées correspondant aux
objets externes qu'il contient.
11.2.3. Cohérence du SGF
Comme dans tout système de gestion de fichier, les
informations sur la structure sont très importantes et doivent être
cohérentes entre elles. Ainsi, la table bitmap ne doit pas indiquer comme
libre un bloc qui serait alloué à un fichier. Conformément
à ce que nous avons dit en 10.2.1, lorsqu'il y a redondance
d'informations, on peut distinguer les informations primaires et les
informations secondaires, celles-ci ayant pour but de donner des accès
efficaces. Dans le cas des informations sur l'état d'allocation des
blocs, les informations primaires sont les descriptions des zones
allouées, et la table bitmap constitue les informations secondaires
permettant d'accélérer les recherches de blocs libres.
De même, pour pouvoir attribuer un Num-ID aux objets
lors de la création, il faut connaître le dernier attribué.
Cette information secondaire est mémorisée dans le descripteur du
volume. L'information primaire est représentée en fait par la plus
grande valeur des Num-ID existant sur le volume.
Pour garantir cette cohérence, HFS maintient un
indicateur dans le descripteur de volume, qui indique que le volume n'a pas
été démonté proprement. Cet indicateur est
écrit sur disque lors du montage en écriture du volume, et remis
à zéro lors du démontage du volume. Il permet donc de
savoir lors d'un montage si une vérification de cohérence est
nécessaire.
11.2.4. Le système HFS Plus
Ce système a pour but de lever les contraintes
rencontrées dans HFS. Nous ne mentionnerons ici que les modifications les
plus importantes pour l'usager:
- La plus importante que nous ayons vu est la
limitation du nombre de quanta d'une partition, impliquant d'avoir une taille de
quantum importante pour les grosses partitions. Cette contrainte est
levée en prenant 32 bits pour les numéros de blocs d'allocation.
Évidemment cela a pour conséquence d'augmenter notablement la
table bitmap, qui devient un fichier, permettant d'homogénéiser
les accès.
- La taille maximale de
chacune des parties d'un fichier est elle aussi augmentée, puisqu'elle
est portée à 263 octets.
- Comme les blocs deviennent plus petits et
peuvent conduire à une fragmentation plus importante, et donc un nombre
plus grand de zones, les groupes ont été portés à 8,
tant dans le descripteur de fichier que dans les entrées du fichier de
description des extensions.
- Les noms des
objets ne sont plus limités à 31 caractères MacRoman
(codage sur 8 bits), puisqu'un nom peut avoir maintenant 255 caractères
Unicode (16 bits). Ceci a conduit à augmenter la taille des nœuds de
l'arbre B* du catalogue (4 Ko par défaut), car plus ces nœuds
contiennent de valeurs, plus la hauteur de l'arbre est
faible.
- Un troisième fichier de volume
organisé en arbre B* a été introduit pour permettre
à terme de gérer plusieurs attributs d'un fichier, mais il s'agit
plus d'ouverture vers l'avenir et d'éviter ainsi d'avoir à
redéfinir un nouveau SGF, car les spécifications complètes
ne sont pas encore complètement définies en mars 1999. Ce fichier
devrait permettre, par exemple, d'avoir plus de deux parties pour un même
fichier, et de pouvoir nommer ces
parties.
11.3. Le système NTFS
Ce système a été créé par
Microsoft pour être le système de gestion de fichier de Windows NT.
Plusieurs systèmes existaient initialement, comme VFAT ou HPFS de OS/2,
mais aucun ne satisfaisait aux critères de fiabilité et de taille
d'un système moderne.
En dehors du premier secteur de la partition, qui contient un
ensemble minimal d'informations comme la localisation du fichier MFT dont il est
question ci-dessous, ce SGF considère que "tout est fichier". Le
formatage d'une partition en volume NTFS consiste donc à créer un
certain nombre de fichiers qui donnent la structure du volume. Nous ne
décrirons que certains de ces fichiers.
- Le fichier des descripteurs de fichiers,
appelé la Master File Table (MFT), qui commence par son propre
descripteur. Il peut commencer n'importe où dans la partition, il est
nécessaire de connaître cet endroit a priori, pour pouvoir
accéder à son descripteur, ce qui est indiqué dans le
premier secteur de la partition. Notons que ce fichier est doublé pour
des raisons de sécurité, la copie étant aussi
repérée par le secteur 0 de la
partition.
- Le fichier du volume, contenant en
particulier le nom du volume.
- Le fichier
bitmap décrivant l'état d'allocation du
volume.
- Le répertoire racine du
volume.
- Le fichier journal qui a pour but de
garantir la fiabilité de la
structure.
11.3.1. Les descripteurs de fichiers
Chaque objet externe reçoit, à sa
création, un numéro qui est l'indice dans la MFT où est
situé son descripteur. La taille de ces descripteurs est fixée
à la création du volume et est comprise entre 1 Ko et
4 Ko, ce qui est donc relativement important. Un objet externe, fichier ou
répertoire, est constitué d'un certain nombre d'attributs qui
peuvent être résidents, c'est-à-dire, rangés dans le
descripteur de l'objet externe lui-même, ou non résident et donc
à l'extérieur de la MFT dans un espace qui lui est alloué
en propre. Voici quelques exemples d'attributs :
- Le nom de l'objet externe sous forme d'une
suite de au plus 255 caractères
Unicode.
- Les informations de base habituelles,
comme les dates de création, modification ou d'accès.
- Les informations de protections de
l'objet.
- Le ou les contenus des fichiers ou
répertoires.
Un même objet externe peut avoir
plusieurs attributs "nom", correspondant au principe des liens physiques
énoncés au §9.4.3.
Si un fichier est suffisamment petit, tous ses attributs, et
donc son contenu se trouvera dans le descripteur. Dans les autres cas, certains
attributs (en particulier les données) seront non
résidents.
NTFS utilise le principe de l'allocation par zone pour les
attributs non résidents d'un objet externe , et la valeur de l'attribut
est remplacée dans le descripteur par la suite des descriptions des zones
allouées. Le nombre de zones est quelconque, chacune étant de
taille quelconque (cf. 8.2.3). La taille du quantum est un nombre entier de
secteurs, ce nombre étant une puissance de 2. Le terme de cluster
désigne les unités d'allocation. Les clusters sont
numérotés sur 64 bits, ce qui implique qu'il n'y a pratiquement
pas de limite aux nombres de clusters d'un volume. Comme un descripteur de zone
doit localiser le premier cluster de la zone et son nombre de clusters, soit 16
octets, une technique de compression est utilisée, d'une part en prenant
son déplacement par rapport au premier cluster de la zone
précédente, et en supprimant les octets nuls en tête de ces
deux valeurs.
La longueur d'un attribut non résident est
mémorisée sur 64 bits, ce qui permet donc des fichiers dont la
taille n'est pratiquement limitée que par l'espace disponible sur le
volume.
Notons que le contenu d'un fichier est un attribut sans nom,
mais l'utilisateur peut créer des attributs nommés qui peuvent
avoir des contenus séparés dans des espaces distincts.
L'implantation de serveur de fichier MacIntosh sur Windows NT utilise ce
principe pour séparer la partie ressource et la partie donnée
(voir HFS).
11.3.2. Les Répertoires
NTFS utilise une arborescence de répertoire. Le contenu
d'un répertoire est organisé en arbre B+, qui se rapprochent des
arbres B* vus plus haut, si ce n'est que les données associées aux
clés sont réparties dans tous les nœuds au lieu de
n'être que dans les feuilles comme sur la figure 11.1. Les entrées
d'un répertoire contiennent les informations suivantes, la
première étant la clé:
- Le nom de
l'objet,
- Le numéro de l'objet dans la
MFT, permettant de localiser son
descripteur.
- Les dates de création,
modification ou d'accès de l'objet,
- La
taille de l'objet
- Le numéro du
répertoire parent qui le contient dans la MFT.
En
fait seuls les deux premiers sont effectivement nécessaires, puisque les
trois derniers se trouvent dans le descripteur de l'objet. Cette duplication a
un avantage et un inconvénient. L'avantage est que l'on a accès
aux informations essentielles de l'objet sans devoir accéder au
descripteur. L'inconvénient est inhérent à la duplication:
toute modification de ces informations doit être portée à
plusieurs endroits sur le disque, sous peine d'avoir des données
incohérentes. Notons qu'il peut paraître surprenant de trouver dans
cette entrée le numéro du répertoire qui contient
l'entrée! En fait, Toutes ces informations, avec la clé, font
partie l'attribut "nom de fichier", présent dans le descripteur du
fichier, et en sont une copie. Or, le numéro du répertoire parent
d'un fichier permet de remonter l'arborescence des fichiers et
répertoires, en retrouvant ainsi le parent de chaque
répertoire.
Le principe des arbres B implique que des nœuds soient
créés ou supprimés au fur et à mesure des
adjonctions ou suppressions. La suppression d'un nœud peut ne pas
être le dernier nœud physique du répertoire, et il faut
prévoir sa réutilisation ultérieure. Ceci se fait en
définissant un attribut "bitmap" pour chaque répertoire qui
indique quels sont les nœuds libres. S'il n'y en a plus, une allocation
d'une nouvelle zone est effectuée, et la table bitmap est mise à
jour pour tenir compte des nœuds libres ajoutés.
11.3.3. Compression de données
NTFS propose une technique de compression/décompression
des fichiers au fur et à mesure des accès. L'idée est de
découper le contenu du fichier par tranche dont la taille correspond
à 16 clusters, et de tenter de compresser chaque tranche
indépendamment les unes des autres. La compression n'est effective que si
elle fait gagner au moins 1 cluster. Dans ce cas, les clusters gagnés
ainsi sont mémorisé dans la suite des descripteurs de zones par
une zone marquée non allouée dont la taille correspond au nombre
de clusters gagnés. A la lecture, l'opération inverse est
effectuée. Notons que la mise en œuvre de la
compression/décompression sur un fichier est mémorisé dans
le descripteur du fichier, l'utilisateur n'ayant pas à s'en
préoccuper ensuite. Évidemment cette technique est coûteuse
en temps processeur, et doit être utilisée à bon escient.
11.3.4. Sécurité par fichier journal
Les opérations mises en œuvre sur les structures
de fichiers, en général, concernent plusieurs secteurs distincts
répartis sur le volume. Les modifications ne peuvent toutes être
portées sur le disque en une seule fois, mais doivent être
effectuées en séquence. Évidemment, les systèmes
tiennent compte de l'éventualité d'une panne qui empêche le
déroulement complet de la séquence et entraîne une
incohérence. Ceci est obtenu en définissant pour chaque
opération l'ordre qui donnera le minimum de dégât en cas de
panne. En particulier, il est préférable de perdre de l'espace
disque plutôt que de risquer d'allouer deux fois le même bloc
à deux objets différents. En fait, il est presque toujours
possible de rétablir la cohérence et retrouver les blocs non
alloués, mais cela peut être coûteux en temps.
Dans le cas des SGF modernes, le risque est aggravé par
le fait que bien souvent les opérations sont effectuées dans des
tampons en mémoire, et que l'écriture de ces tampons sur disque
est effectuée plus tard, pour gagner en performance et en
efficacité (principe de l'écriture paresseuse). Par exemple, une
création de fichier donnera souvent lieu dans un avenir proche à
une ou plusieurs allocations d'espace disque. Le report des écritures de
la table bitmap peut avoir pour conséquence qu'elle ne sera écrite
qu'une seule fois lorsque tout sera terminé.
La structuration d'un volume en NTFS contient un fichier
particulier, dit fichier journal, qui va avoir un rôle analogue au fichier
journal des systèmes de gestion de bases de données classiques,
dans lequel sera mémorisée la séquence des actions
effectuées sur le disque dans le but de pouvoir soit les refaire soit les
défaire après une panne. Cette utilisation fait appel à la
notion de transaction, qui signifie, entre autre, que l'on garantit que toutes
les opérations élémentaires de la transaction sont
effectuées, même en cas de panne, ou que aucune n'est faite.
Expliquons brièvement le déroulement des opérations lors de
la création d'un fichier avec allocation d'espace. Les opérations
sont les suivantes:
- Initialisation d'une transaction.
- Création d'un descripteur du
fichier dans la MFT.
- Création de l'entrée dans le
répertoire parent,
- Mise à l'état non libre des bits
correspondants aux clusters alloués, dans la bitmap,
- Clôture de
la transaction.
Les opérations 2, 3 et 4 sont
faites dans des tampons en mémoire, et lors de la clôture de la
transaction, il est probable que ces tampons n'ont pas encore été
écrits sur disque. Chacune de ces opérations donne lieu à
un enregistrement dans le fichier journal qui décrit comment "refaire" et
comment "défaire" l'opération correspondante. En fait ces
enregistrements sont mis dans des tampons en mémoire, en vue d'une
écriture ultérieure, comme pour tout fichier. Cependant le
gestionnaire de ces tampons fera en sorte que les tampons du fichier journal
soient écrits sur disque avant l'écriture des autres tampons. De
plus, périodiquement, l'état des transactions ainsi que la liste
des tampons en mémoire non encore écrits sur disque sont
enregistrés dans le fichier journal. En cas de panne une analyse du
fichier journal permet de savoir les transactions clôturées dont
les actions n'ont pas été portées physiquement sur disque
et qui doivent donc être refaites, ou les transactions non
clôturées dont les actions portées physiquement sur disque
doivent être défaites.
11.4. Le système ext2fs de Linux
Linux est un système d'exploitation qui s'apparente
fort à Unix, tout en étant un logiciel libre. Le système de
fichier initial était dérivé de celui du système
Minix, lui aussi dérivé d'Unix pour l'enseignement. Le SGF de
Minix étant cependant trop contraint, un nouveau système de
gestion de fichier a été écrit, ext2fs.
11.4.1. La représentation de l'espace
Comme d'habitude, l'ensemble du disque est
découpé en blocs dont la taille est un multiple (puissance de 2)
de la taille d'un secteur. Ext2fs pratique l'allocation par bloc de taille fixe,
à plusieurs niveaux (cf. 8.3.2). Les descripteurs d'objets externes sont
représentés dans ce qui est appelé un inœud, qui sont
regroupés dans une table, l'indice dans la table, appelé le
numéro du inœud (i est là pour integer), identifiant de
façon unique cet objet. Une table bitmap décrit l'état
d'allocation des inœuds, et une autre décrit l'état
d'allocation des blocs. Pour des raisons de performances, en particulier sur les
gros disques, ces tables sont morcelées et réparties dans la
partition.
Une partition est découpée en groupes de
même taille, chaque groupe comportant 6 parties:
- Le super bloc, qui contient les
informations de structure du volume.
- La
liste des descripteurs de groupe, qui localise sur le disque les informations
essentielles de chaque groupe (localisation des
tables).
- La table bitmap d'état
d'allocation des blocs du groupe.
- La
table bitmap d'état d'allocation des inœuds du
groupe.
- La table des inœuds du
groupe.
- Les blocs de
données.
Le super bloc et la liste des descripteurs
de groupe sont donc répétés au début de chaque
groupe, pour des raisons de fiabilité. Lors du montage, on ne lit en fait
que ceux du premier groupe. Cette séparation en groupes doit plus
être vue comme une répartition des données sur le disque,
dans le but d'améliorer les performances. La taille d'un groupe est
d'ailleurs limitée, puisque chaque table bitmap d'un groupe doit tenir
dans un seul bloc. Si la taille de la partition est importante, il y aura
beaucoup de groupes.
Les groupes ont pour but de rapprocher dans un espace physique
proche les informations qui sont reliées entre elles. Ainsi, lors d'une
allocation d'un inœud, on cherchera de préférence dans le
groupe du répertoire où il est référencé; de
même, lors de l'allocation d'un bloc, on cherchera d'abord le bloc qui
suit le dernier alloué à l'objet, puis dans son voisinage
immédiat (±32), puis dans le même groupe et enfin dans les
autres groupes.
Un descripteur d'objet externe contient évidemment le
type de l'objet, des informations pour sa protection, sa longueur, les dates
habituelles de création, modification, accès et destruction, ainsi
que les informations de localisation du contenu, qui sont semblables à
celles de la figure 8.4 (la seule différence est qu'il y a en
général 12 blocs directs au lieu de 10). La taille d'un objet
externe est limité à 2 Go, mais la taille d'une partition
peut atteindre 4 To.
11.4.2. Les répertoires
Ext2fs gère une arborescence de fichiers. Le contenu
d'un répertoire étant une liste d'entrées
constituées de couples <inœud, nom>, le nom étant
limité à 255 caractères. Les deux premières
entrées d'un répertoire sont les entrées "." et ".."
habituelles. Il est possible d'avoir plusieurs noms ou chemins d'accès
pour le même inœud. Ceci a pour conséquence que la suppression
d'une entrée dans un répertoire n'entraîne pas
obligatoirement la suppression du inœud correspondant. Celle-ci ne sera
effective que s'il n'existe plus d'entrée associée à ce
inœud dans aucun répertoire. En dehors de la suppression d'une
entrée dans un répertoire, qui n'affecte donc que cette
entrée, toutes les autres opérations effectuées par l'un
des chemins aura les mêmes répercussions par l'autre.
Ce système permet aussi la création de liens
symboliques (cf. 9.4.3). Dans ce cas, il s'agit de créer un objet externe
(avec inœud et contenu), du type lien symbolique, et dont le contenu sera
le chemin d'accès à l'objet relié. Rappelons que dans ce
cas la recherche de l'objet externe relié implique la
réévaluation du chemin d'accès.
11.4.3. Sécurité
Comme beaucoup de systèmes, ext2fs est basé sur
l'utilisation de caches mémoire des blocs disques, l'écriture des
blocs modifiés étant reportée (écriture paresseuse).
Cela peut avoir pour conséquence des incohérences dans la
structure du volume. L'écriture d'un bloc est effective lorsque le tampon
qu'il occupait est récupéré pour un autre bloc. De plus,
cette écriture est forcée automatiquement à une
période régulière. Comme tous les systèmes, il est
cependant recommandé de toujours l'arrêter par la commande
associée. Dans ext2fs, à chaque objet externe, est attaché
un indicateur qui, lorsqu'il est positionné, demande que le inœud et
les blocs indirects sur disque soient synchrones avec leur contenu en
mémoire, c'est-à-dire, que toute modification en mémoire
soit portée immédiatement sur le disque, avant de retourner au
programme d'application. Pour l'utilisateur, la fin d'exécution de
l'opération signifie pour lui un état cohérent de la
structure disque, en regard de son fichier.
Notons deux attributs définis par ext2fs et
attachés à chaque fichier :
- L'attribut de "secret" implique que, lors de
la destruction du fichier, le contenu doive être effacé en le
remplissant de données aléatoires. Cela évite que des
données sensibles puissent être vues lors de la réallocation
des blocs qui les contenaient.
- L'attribut de
"récupération" permet la récupération d'un fichier
détruit, jusqu'à un certain
point.
11.5. Structuration en couche du système
Certains systèmes permettent de manipuler, au
même moment, des volumes structurés différemment. C'est
assez naturel lorsque l'un des SGF est une extension de l'autre par le
même concepteur, comme par exemple HFS et HFS Plus. La
caractéristique de standard de fait de FAT fait que pratiquement tous les
systèmes implantent ce SGF en plus de leur propre SGF
propriétaire. Windows NT reconnaît et gère FAT, VFAT, HPFS
(de OS/2) et NTFS. Il ne reconnaît pas HFS, mais est capable de simuler un
serveur de fichier de ce type sur un réseau, en s'appuyant sur NTFS.
Linux permet la manipulation de tous les SGF évoqués dans ce
chapitre, au moins en lecture, si ce n'est en écriture.
La reconnaissance simultanée de plusieurs SGF est en
général basé sur un découpage du logiciel en
couches, en définissant les spécifications entre les
couches:
- Le système de fichier virtuel (SFV)
est la vue homogène de tous les SGF réels. Il est défini en
interne en terme de structures de représentations et d'opérations
de manipulations de ces structures.
- Le
système de tampons mémoire qui contiennent les blocs disque (le
cache).
- Le disque abstrait est une vue
homogène des tous les disques supportés par l'installation. Il
définit un ensemble d'opérations d'accès disques
élémentaires indépendantes des périphériques
physiques eux-mêmes .
Les couches du logiciel sont
les suivantes:
- La couche haute, proche de l'application,
implante les opérations d'accès nécessaires aux programmes
d'applications en voyant le système de fichier avec la structure de
SFV.
- La couche intermédiaire,
liée à un SGF, assure l'interface entre le SFV et les tampons
mémoire. Elle assure la transformation entre les structures du SFV et du
SGF particulier et implante les opérations du SFV, selon les
caractéristiques du SGF, en se servant de ces
tampons.
- Le gestionnaire de cache gère
les tampons mémoire et lance les opérations nécessaires
vers le disque abstrait.
- Les pilotes des
disques, liés aux périphériques eux-mêmes, implantent
les opérations du disque abstrait en terme d'opérations
concrètes du disque.