9
La désignation des objets externes
Nous avons dit précédemment que l'accès
à un objet externe dans un programme se faisait par
l'intermédiaire d'un fichier logique, point de vue du programmeur, qui
devait être relié à l'exécution avec un tel objet
externe. L'établissement du lien proprement dit est réalisé
par l'opération d'ouverture du fichier. Les paramètres de cette
opération doivent permettre de localiser l'objet externe, et d'en trouver
les caractéristiques.
9.1. La définition d'une liaison
Les avis divergent sur l'endroit où doit se trouver
cette définition. Dans certains systèmes, cette définition
ne fait pas partie du programme, mais de son environnement. Aussi, c'est le
langage de commande qui propose des commandes permettant cette
définition. Ceci offre l'avantage de bien faire la séparation
entre l'algorithme et les objets sur lesquels s'exécute l'algorithme. Par
ailleurs, cela permet de prendre en compte un grand nombre de paramètres,
avec des valeurs par défaut pour chacun d'eux, ce qui n'est pas toujours
possible dans les langages évolués. Enfin cela évite de
faire dépendre certaines fonctionnalités du système, de la
possibilité de les exprimer dans les langages évolués.
Cette méthode est souvent appliquée sur les gros systèmes
qui privilégient le traitement par lots, et qui peuvent recevoir des
périphériques divers, impliquant un nombre important de
paramètres de la définition d'une liaison (près de 150
paramètres pour une commande //DD
d'IBM). Cela permet également au système de savoir quels seront
les besoins du programme avant d'en lancer l'exécution, et de la retarder
si ces besoins ne peuvent être satisfaits. En général, la
mise en correspondance entre le programme et le langage de commande est obtenue
par un nom logique (identificateur) donné au fichier explicitement par le
programmeur ou implicitement par le traducteur, et repris par l'utilisateur dans
la commande de définition.
Par opposition, d'autres systèmes supposent que les
paramètres de l'ouverture d'un fichier sont déterminés par
le programme et sont partie intégrante de la demande d'exécution
de l'opération. On évite de trop fortes contraintes entre les
langages et le système en ayant assez peu de paramètres, dont au
moins un est une simple chaîne de caractères qui n'est pas
interprétée par le langage évolué, et qui joue ainsi
le rôle de “commande”. Cette méthode offre l'avantage
de permettre au programme d'avoir une certaine maîtrise sur la
définition de la liaison. En particulier, lorsque le programme est
utilisé de façon interactive, il est possible de cacher à
l'utilisateur du programme la complexité de l'interface système
concernant les objets externes, sans pour autant devoir toujours relier le
fichier avec le même objet externe.
Lorsque l'objet externe est directement un
périphérique physique, la définition de la liaison est
relativement simple, car ces périphériques existent en nombre
très limité, et leurs nombres ou caractéristiques varient
très peu pour une installation donnée. On peut donc leur donner un
nom mnémonique spécifique qui est connu de tous les utilisateurs.
Ce nom est ensuite utilisé par le système pour en trouver la
localisation et les caractéristiques au moyen d'une recherche dans ses
tables internes. Il trouve ainsi, non seulement le descripteur du
périphérique, mais également les procédures de
traitement des opérations qui le concernent. Par ailleurs ces tables
permettent de savoir l'état libre ou occupé de ces
périphériques, et d'en assurer ainsi la gestion.
Lorsque l'objet n'est pas un périphérique, mais
est un fichier physique sur un support magnétique, la définition
doit permettre de:
- localiser le support physique de
l'objet,
- localiser l'objet sur le
support,
- déterminer les
caractéristiques de l'objet.
La notion de volume
est souvent utilisée pour permettre la localisation du support, et la
notion de répertoire pour permettre la localisation sur le support ainsi
que la détermination des caractéristiques de l'objet lorsqu'il
existe déjà.
9.2. La notion de volume
La localisation du support par localisation du
périphérique n'est pas acceptable dès que le support
lui-même est amovible. Le périphérique permet
d'accéder au support qui est actuellement monté sur ce
périphérique. Pour l'utilisateur, il importe plus d'accéder
à un support donné que d'accéder au
périphérique sur lequel il est monté. Pour la bonne
exécution des opérations, il importe plus au système de
savoir quel périphérique est concerné par les
opérations. En première approche, on appelle volume un
support d'informations, tel que, par exemple, une bande magnétique, une
cartouche, une disquette, ou une pile de disque (une gamelle). Il est important
de noter que le volume est quelque chose que l'on manipule comme un tout, et
que, comme support d'objets externes, il a une structure qui lui est propre. En
tant que support, il est de nature physique, mais en tant que structure, il est
de nature logique.
Le fait qu'il puisse être amovible, implique qu'il peut
ne pas être accessible, et c'est alors sa nature physique seule qui nous
intéresse, puisqu'on ne peut lire alors son contenu. Au contraire, pour
être accessible, il doit être disponible sur un
périphérique particulier, et sa structure reconnue, et c'est donc
sa nature logique seule qui nous intéresse. On appelle montage d'un
volume l'opération qui rend accessible son contenu, et
démontage l'opération qui le rend inaccessible.
9.2.1. La structuration d'un volume
Le fait qu'un volume puisse être amovible implique que
l'ensemble des informations qui y sont mémorisées doivent
être suffisantes pour en définir le contenu. Il est donc
nécessaire que l'on y trouve deux types d'informations:
- les caractéristiques des objets externes
qu'il contient, ainsi que leur localisation sur le
volume,
- les informations permettant au
système d'y créer de nouveaux objets externes sans écraser
ceux qui y sont déjà.
Le permier type
d'informations est directement lié à la localisation des objets
sur le support. Nous verrons ultérieurement les structures permettant de
résoudre ce problème. Le deuxième type d'informations est
en fait la représentation de l'espace libre dont nous avons parlé
dans le chapitre précédent.
Lorsqu'un volume n'est pas monté, c'est sa nature
physique qui nous intéresse. Encore faut-il être capable de
l'identifier parmi l'ensemble des volumes existants pour l'installation. Ceci
passe en général par une étiquette collée
directement sur le support, qui permet à l'opérateur
d'accéder à cette identification. Pour permettre un contrôle
par le système de cette identification, le contenu de cette
étiquette est souvent recopié dans le volume lui-même. C'est
ce que nous appellerons le nom du volume (en Anglais le label du
volume).
L'ensemble de ces informations de gestion doivent
évidemment être placées à des endroits
prédéfinis par le système de façon à lui
permettre de les retrouver. Ceci doit être fait avant de faire un
accès quelconque au support. C'est ce que l'on appelle le formatage du
volume. Il consiste à lui donner un nom, à construire la
représentation de l'espace libre initial et à initialiser la
structure de données qui permet de localiser les objets existants sur le
volume.
Ce formatage peut être conforme à un standard
international (ANSI) ou national (AFNOR), ce qui permettra aux utilisateurs
d'échanger ces volumes pour communiquer des données. C'est souvent
le cas pour les bandes magnétiques. Ce formatage peut également
être un “standard de fait”, défini par un
système et universellement adopté par d'autres systèmes,
comme par exemple les disquettes MS-DOS. Ce formatage peut être propre
à un constructeur pour tout ou partie de sa gamme. C'est souvent le cas
pour les disques, car ils sont assez peu utilisés pour permettre la
communication entre machines, mais essentiellement pour la mémorisation
locale. La portabilité n'est pas alors un critère important, alors
que l'efficacité de l'exploitation du support l'est.
9.2.2. Le montage de volume
L'opération de montage de volume est constituée
de trois étapes: choix du périphérique, montage physique du
volume sur le périphérique et modification des tables du
système. Lorsque ces opérations sont terminées, le
système connaît l'association entre le nom du volume logique et le
périphérique. L'utilisateur n'a plus à s'en
préoccuper et peut donc localiser le périphérique par le
nom du volume logique. L'opération de démontage est elle en deux
étapes: modification des tables du système puis démontage
physique. Il est en effet important qu'il y ait accord préalable entre
l'opérateur et le système pour qu'aucun lien ne soit établi
au moment du démontage physique, ce qui pourrait nuire à la
cohérence des objets sur le support.
Le choix du périphérique, que l'on appelle
l'allocation, peut être fait par le système de façon
automatique. En effet, le système connaît un besoin immédiat
d'un programme, soit par la présence de la définition d'un lien
dans les commandes qui précèdent la demande d'exécution
d'un programme, soit par une demande d'établissement du lien par le
programme. Si le volume désiré n'est pas monté, le
système peut alors allouer lui-même un périphérique
parmi ceux qui sont libres, c'est-à-dire, ceux qui ne sont pas
associés à un volume, et demander à l'opérateur de
faire le montage physique du volume concerné sur ce
périphérique. Cette méthode est surtout appliquée
lorsque la définition des liens est donnée dans le langage de
commandes, car le système peut anticiper les allocations et faire les
choix en fonction de l'ensemble des besoins de tous les programmes qui sont en
attente d'exécution.
L'allocation peut être faite par l'opérateur, par
anticipation, car il a connaissance du besoin avant qu'il ne soit effectivement
exprimé au système. C'est souvent le cas lorsque l'on
désire permettre les accès aux objets mémorisés sur
un volume pendant une période définie de la journée. Notons
que l'opérateur peut constater de visu l'état libre d'un
périphérique par le fait qu'aucun support n'y est actuellement
monté physiquement.
Le montage physique est une opération manuelle (sauf
pour les robots spécialisés de montage de cartouches).
L'opérateur retrouve dans un stock plus ou moins important de volumes,
celui qui est demandé et qui est désigné par son
étiquette, et le place sur le périphérique alloué.
Durant cette opération, le périphérique est
“déconnecté” de l'ordinateur, c'est-à-dire, que
celui-ci ne peut y accéder. On dit qu'il est en mode local (ou
encore off line). Lorsque le placement est terminé,
l'opérateur le fait passer en mode distant (ou encore on
line). Cette opération n'est en général pas
instantanée, car elle demande, par exemple, un positionnement sur les
dérouleurs de bande, et une mise en rotation sur les
tourne-disques.
Lorsque le montage physique est terminé, le
système doit mettre à jour ses tables. Ceci peut être fait
manuellement par une commande de l'opérateur, ou automatiquement lorsque
le système détecte le passage en mode distant d'un
périphérique. Dans ce dernier cas, on dit qu'il y a
reconnaissance automatique de volume. Le système peut alors lire
le nom du volume sur le périphérique, et mémoriser dans ses
tables ce nom associé au périphérique. Notons que
même si l'allocation de périphérique a été
faite par le système, l'opérateur peut néanmoins placer le
volume sur un autre périphérique libre. C'est bien au moment
où le système lit le nom du volume sur le
périphérique que l'association est faite. Avant cet instant, il ne
s'agit que de propositions.
9.2.3. La relation entre volume et support
La notion de volume est évidemment liée au
support, ce qui implique des contraintes de taille de l'espace total, qui
peuvent être jugées trop fortes. D'une part, un support peut
être de taille trop faible pour contenir un objet externe donné,
qui pourtant doit se trouver sur un seul volume. D'autre part, nous avons vu
dans le chapitre précédent qu'un support de très grande
taille était parfois mal adapté pour recevoir beaucoup de petits
objets.
Le premier cas est surtout celui des bandes
magnétiques. Certains systèmes offrent la notion de
multi-volumes. Elle peut être vue comme une facilité du
logiciel, de définir la localisation du support non plus au moyen d'un
volume unique, mais par une collection de volumes. Le système
considèrera la collection comme une seule bande, les volumes étant
dans l'ordre où la collection est définie.
Le deuxième cas est celui des disques. Dans ce cas, il
est assez courant maintenant de découper l'ensemble de l'espace d'un
disque en partitions qui sont des portions indépendantes du
disque, et qui en tant que tel seront considérées comme des
supports séparés. Chaque partition est ensuite structurée
en volume. Lorsque le disque est monté, (passage en mode distant), le
système explore son découpage en partition pour identifier chacun
de ces supports permettant ensuite le montage des volumes qui les structurent.
Certains systèmes combinent les deux principes, en
permettant d'agréger plusieurs partitions situées
éventuellement sur des disques différents en un seul support qui
peut ainsi être structuré en un volume unique. Cela permet
d'obtenir un volume de grande taille à partir de plusieurs petits
disques, ou d'utiliser au mieux de petites partitions restantes
éparpillées sur plusieurs disques. Notons que la
répartition des données d'un volume sur plusieurs disques peut
améliorer les performances, car elle permet les accès
simultanés. Nous verrons d'autres applications dans le chapitre
suivant.
9.3. La notion de répertoire
Lorsque la localisation du support physique est obtenue, il
faut localiser l'objet externe sur le support. La méthode qui consiste
à le localiser explicitement par les informations numériques dont
nous avons parlé dans le chapitre 8, a été utilisée
pendant quelques années, mais s'est avérée très vite
inappropriée car elle est beaucoup trop sujette à erreurs. Il est
plus judicieux de donner, aux objets externes, un nom symbolique
constitué d'une chaîne de caractères. Un
répertoire (ou encore un catalogue, en anglais
directory) est en fait une table qui associe le nom symbolique d'un objet
externe et le descripteur de cet objet externe, c'est-à-dire, les
informations de localisation de l'objet sur le support ainsi que ses
caractéristiques. Il est naturel de conserver ces informations sur le
support lui-même, puisqu'elles sont nécessaires si et seulement si
le volume correspondant est monté.
9.3.1. Le répertoire sur bande magnétique
Sur une bande magnétique, la nature séquentielle
du support conduit naturellement à faire précéder l'objet
externe d'un bloc spécial (appelé label de fichier) qui
contiendra son nom symbolique et ses caractéristiques. Aucune information
de localisation n'est alors nécessaire, puisqu'il est situé
immédiatement derrière, si ce n'est un autre bloc spécial
(appelé label de fin de fichier) qui en indique la fin. Pour
accélérer les accès lors de la recherche d'un objet externe
par son nom, la suite des blocs est structurée à l'aide de
blocs drapeaux: ce sont des blocs physiques sur la bande, qui sont
écrits par des commandes particulières et qui sont reconnus par le
matériel même lorsque le déroulement se fait à grande
vitesse (défilement rapide avant ou arrière). La figure 9.1 donne
un exemple d'une telle structuration. Notons que si le dernier fichier est
multi-volumes, la marque de fin de fichier n'est pas présente, et on
trouve directement la marque de fin de volume.
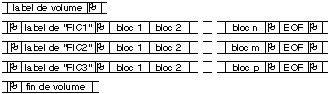
Fig. 9.1. Exemple de structuration d'une
bande magnétique. O représente un bloc drapeau, EOF le label de
fin de fichier.
9.3.2. Répertoire simple sur disque
Sur disque, le secteur 0 est en général
dédié pour donner les informations de base sur sa structure. Il
faut en effet que ce soit au même endroit sur tous les volumes, et les
fabricants garantissent que ce secteur est exempt de tout défaut. Si le
disque est partitionné, son secteur 0 définit la carte
d'implantation des partitions, et le secteur 0 de chacune d'elles reçoit
les informations de base sur la structure de la partition. Ce secteur peut donc
en particulier contenir le nom du volume, mais aussi la localisation des
informations nécessaires à la gestion de l'espace libre.
Une première solution consiste à réserver
une partie dédiée de l'espace à la représentation du
répertoire. Si elle est de taille fixe, cela limite le nombre d'objets
externes que l'on peut mettre sur ce disque. Cette taille doit alors être
judicieusement choisie. La localisation du répertoire peut être
fixe ou variable en fonction du volume. Lorsque sa localisation est variable,
elle est en générale repérée par des informations
situées dans le secteur qui contient le nom du volume. Lorsque le disque
doit recevoir des objets externes appartenant à plusieurs utilisateurs
différents et indépendants, il peut être gênant
d'avoir un seul répertoire, car les noms des objets doivent être
distincts, et les utilisateurs doivent alors se mettre d'accord sur les noms
qu'ils utilisent. Une solution consiste à ajouter implicitement devant
les noms des objets les noms des utilisateurs.
On peut aussi découper le répertoire en tranche,
chaque tranche étant attribuée à un utilisateur
particulier. En fait, on dispose plutôt d'un
super-répertoire qui permet la localisation des répertoires
individuels des utilisateurs. Seul ce super-répertoire doit être
localisé de façon absolue, les autres sont
considérés comme des objets externes particuliers, qui peuvent
être créés au fur et à mesure des besoins. MS-DOS,
dans ses premières versions, mais aussi certains gros systèmes
utilisent cette méthode.
9.3.3. Arborescence de répertoires
Lorsque le nombre d'objets externes devient important, les
solutions précédentes ne sont plus viables. Dans un système
Unix, par exemple, on a constaté qu'il y avait 47000 fichiers sur un
disque de 400 Mo. Même si on suppose que ces fichiers appartiennent
à 100 utilisateurs différents, cela donne 470 fichiers en moyenne
par utilisateurs. Même sur un ordinateur personnel, il n'est pas rare
d'avoir près de 5000 fichiers sur un disque de 500 Mo. Si tous ces
fichiers sont repérés dans un répertoire unique, cela
implique d'une part de bien choisir les noms pour n'avoir pas de confusion,
d'autre part cela entraîne des temps de recherche importants dans le
répertoire.
La solution qui est couramment adoptée actuellement est
de partitionner l'espace des noms des objets externes. Notons que, dans
l'approche du paragraphe précédent, nous avions introduit la
notion de super-répertoire permettant de disposer de répertoires
séparés pour les utilisateurs. Ceci nous a conduit à
considérer qu'un répertoire était un objet externe
particulier. La généralisation de cette idée consiste
à considérer qu'un répertoire est une table qui associe un
nom et un descripteur d'objet externe au sens large, c'est-à-dire fichier
de données manipulé par un programme, ou répertoire. Au
lieu d'un répertoire plat, on obtient une arborescence de
répertoire, dont seule la racine est localisée de façon
absolue.
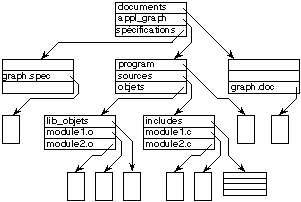
Fig. 9.2. Exemple d'arborescence de
répertoire.
La figure 9.2 donne un exemple d'une telle arborescence. Le
répertoire racine contient trois entrées pour les
répertoires de nom documents,
appl_graph et
specifications. Le répertoire
appl_graph contient aussi trois
entrées, la première associe le nom
program et un fichier, alors que les deux
autres associent les noms sources et
objets avec deux répertoires. Enfin,
le répertoire sources contient une
entrée pour le répertoire
includes et deux entrées pour les
fichiers de nom module1.c et
module2.c. Cet exemple montre tout le
bénéfice qu'un utilisateur peut retirer d'une arborescence, en
regroupant dans un même répertoire des entités qui
présentent une propriété de cohérence donnée.
Ainsi, le répertoire documents
pourrait regrouper les fichiers de documentation, et le répertoire
sources regrouper les fichiers sources de
l'application appl_graph, dont
includes constitue le sous-groupe des
fichiers qui peuvent être inclus dans les fichiers sources par les
préprocesseurs.
La désignation d'un objet externe doit permettre d'une
part d'identifier le volume qui contient l'objet et d'autre part de localiser
l'objet sur ce volume. Lorsqu'on a une arborescence de répertoires, la
localisation de l'objet sur le volume consiste donc à définir le
chemin depuis la racine jusqu'à l'objet dans cette arborescence. C'est
donc une suite de noms qui doivent être utilisés, pour
désigner la suite des répertoires à parcourir pour
atteindre l'objet recherché. Chacun de ces noms permet de désigner
le répertoire suivant (ou l'objet recherché) dans le
répertoire courant. Un nom étant une chaîne de
caractères, il est courant de définir une structure lexicale
rudimentaire qui permet de définir sous la forme d'une seule chaîne
de caractères l'identification du volume et la suite de noms
précédente. C'est ce que l'on appelle le nom absolu de
l'objet ou encore le chemin d'accès à l'objet (en
Anglais le pathname).
Par exemple, les versions récentes de MS-DOS utilisent
le caractère “:” comme
séparateur entre le nom du volume (en fait le nom symbolique du
périphérique) et le nom de l'objet sur le volume, et le
caractère “\” comme
séparateur entre les noms de répertoires, ce que l'on peut
énoncer de la façon suivante:
[nom_de_volume:]{\nom_répertoire}\nom_objet
Ainsi le nom absolu
“C:\appl_graph\sources\module1.c”
désigne un objet sur le volume C.
Sur ce volume, il faut rechercher dans le répertoire racine le
répertoire appl_graph, puis dans
celui-ci le répertoire sources, et
dans ce dernier l'objet
module1.c.
9.4. Construction d'une arborescence unique à la Unix
La structure de désignation à laquelle nous
venons d'aboutir dans le paragraphe précédent s'apparente à
une arborescence unique: à la racine se trouve la désignation des
volumes ou des périphériques, permettant l'accès à
une sous-arborescence locale à chaque volume. Le système Unix
présente à l'utilisateur l'ensemble des objets sous une
véritable arborescence unique et une désignation uniforme dans
cette arborescence.
9.4.1. Les fichiers spéciaux comme périphériques
On peut remarquer qu'une entrée particulière
d'un répertoire associe un nom, local au répertoire, et un
descripteur d'objet. Si l'objet est un fichier au sens classique du terme, le
descripteur doit contenir les caractéristiques du fichier (organisation,
par exemple) et les informations de localisation du contenu. Si l'objet est un
répertoire, le descripteur doit contenir également les
caractéristiques, en particulier, l'indication qu'il s'agit d'un
répertoire, et les informations de localisation du contenu. Ce
descripteur doit donc permettre de distinguer la nature fichier ou
répertoire de l'objet associé.
L'idée des concepteurs d'Unix est que l'on peut
créer un descripteur de nature différente des
précédentes, appelé fichier spécial, pour
désigner cette fois un périphérique de l'installation. Un
tel descripteur contient, en particulier, un numéro de
périphérique majeur qui détermine le type du
périphérique (terminal, disque, bande, etc...) et un
numéro de périphérique mineur qui détermine
le périphérique particulier du type correspondant.
Évidemment ces numéros n'ont de sens que sur une installation
donnée.
Dans la plupart des installations, un répertoire
particulier (/dev) regroupe les
descripteurs de tous les périphériques, et les noms locaux qui
leur sont associés. Par exemple
/dev/lp désigne l'objet de nom
lp dans le répertoire de nom
dev situé à la racine. C'est
la nature du descripteur de l'objet qui permet au système de constater
qu'il s'agit de l'imprimante de l'installation. L'intérêt est donc
essentiellement dans la désignation uniforme ainsi obtenue.
9.4.2. Le montage de volume dans Unix
Comme nous l'avons dit, un volume contient sa propre
arborescence locale qui permet la désignation des objets sur le volume.
Pour obtenir une arborescence unique lorsque l'on monte un volume, il faut
raccrocher cette arborescence locale quelque part dans l'arborescence courante.
L'option adoptée par le système est de permettre de la raccrocher
n'importe où, à la place d'un répertoire. L'arborescence
locale vient alors remplacer la sous-arborescence issue de ce répertoire.
En général, on utilise un répertoire vide, mais ce n'est
pas obligatoire. Si ce n'est pas le cas, les objets qu'il contenait sont
momentanément inaccessibles.
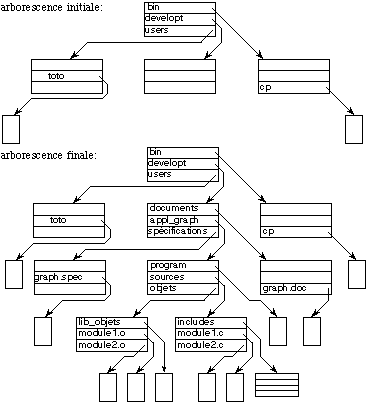
Fig. 9.3. Exemple de montage d'un volume
dans Unix. L'arborescence locale du volume remplace l'arborescence de
/developt.
La figure 9.3 montre le résultat du montage du volume
dont l'arborescence a été présentée en figure 9.2,
sur le répertoire de nom absolu
/developt dans l'arborescence initiale.
Lorsque le montage est terminé, on accède aux objets du volume en
faisant précéder le nom local de l'objet sur le volume par le nom
absolu du répertoire sur lequel le volume a été
monté, comme, par exemple, dans:
/developt/appl_graph/sources/module1.c
En général les opérations de montage sont
effectuées par l'opérateur qui choisit le
périphérique (allocation manuelle) et le répertoire sur
lequel les volumes sont montés. Pour l'utilisateur, il ne voit qu'une
arborescence unique, et n'a plus à se préoccuper du support de ses
objets. Comme les périphériques sont aussi désignés
dans l'arborescence, il a donc un mécanisme uniforme de
désignation de tous les objets externes.
9.4.3. Les fichiers multi-répertoires
Lorsque plusieurs utilisateurs travaillent sur un projet
commun, ils doivent pouvoir accéder à des fichiers qu'ils ont en
commun. En fonction de ce que nous avons dit ce n'est pas difficile, puisque
tout objet a un nom absolu. Il arrive souvent que chacun aimerait le voir
à un endroit précis de l'arborescence, qui n'est pas le même
pour tous. Certains systèmes qui offrent une arborescence de fichiers
(VMS, Unix, Multics) permettent de situer un même fichier à
plusieurs endroits de cette arborescence. Évidemment, nous n'avons plus
tout à fait un arbre, mais un graphe orienté sans
cycle.
Deux méthodes sont utilisées pour cela. La
première utilise ce que l'on appelle les liens physiques. Ils ne
sont autorisés que pour les fichiers de données (et donc interdits
pour les répertoires ou les fichiers spéciaux). Pour pouvoir
prendre en compte les liens physiques, les descripteurs d'objets ne sont pas mis
dans les répertoires, mais dans une zone particulière du disque,
et sont repérés par un numéro appelé
i-nœud dans le système Unix. Les répertoires associent
les noms symboliques locaux et les numéros de descripteurs d'objets. Il
est ainsi possible de créer une autre association entre un nom et ce
numéro dans un autre répertoire. Le fichier possède alors
deux (ou plus) noms absolus. L'utilisateur ne détruit plus les objets
directement, mais les liens physiques vers ces objets. La destruction d'un objet
externe intervient lorsque le système constate qu'il n'y a plus de lien
physique pour cet objet. Évidemment si un utilisateur détruit un
lien physique dans un répertoire vers un objet commun, et recrée
un nouvel objet de même nom dans ce répertoire, l'objet ancien
reste désigné par ses autres noms symboliques absolus.
La deuxième méthode utilise ce que l'on appelle
les liens symboliques. Lorsque l'on crée un lien symbolique
n dans un répertoire pour un objet
O situé ailleurs, le système
n'associe pas le nom local avec le descripteur de l'objet
O, mais avec le nom symbolique absolu de
l'objet O. L'objet
O peut d'ailleurs ne pas exister au moment
où l'on crée le lien symbolique. Par contre lorsque l'on cherche
à accéder à l'objet par le nom
n, le système interprètera
à ce moment le nom symbolique absolu qui lui est associé pour
trouver O. Évidemment comme le nom
symbolique absolu est réinterprété à chaque
désignation qui utilise n, cela est
plus coûteux, mais on est sûr alors de ne pas trouver une ancienne
version de l'objet. Par ailleurs, les liens symboliques sont autorisés
pour les objets de toute nature, y compris les répertoires. Cette
méthode se généralise bien aux systèmes
répartis.
9.4.4. La désignation par rapport à l'environnement
L'arborescence de répertoire conduit à une
désignation des objets relativement longue. On a donc cherché
à alléger cette désignation. De fait, si une installation
comporte plus de 100 000 objets externes, un utilisateur n'a besoin
d'accéder qu'à une petite partie d'entre eux à un instant
donné. Plusieurs solutions ont été proposées, en
particulier, la notion de répertoire de travail et la notion de
règles de recherche.
Pour tout utilisateur actif, le système
privilégie un répertoire particulier de l'arborescence, et que
l'on appelle le répertoire de travail. Des commandes permettent à
l'utilisateur de changer son répertoire de travail à tout instant.
Outre la désignation des objets par leur nom absolu, c'est-à-dire,
en partant de la racine de l'arborescence, l'utilisateur peut désigner un
objet en donnant son chemin d'accès à partir de ce
répertoire courant. En Unix, tout chemin d'accès ne
commençant pas par “/”
est considéré comme relatif au répertoire courant. Il en va
de même pour MS-DOS, si le chemin ne commence pas par
“\”. Pour permettre de remonter
dans l'arborescence, chaque répertoire de ces systèmes contient
une entrée, dont le nom est prédéfini
“..”, qui est associée
au répertoire situé au-dessus dans l'arborescence. Pour être
complet, signalons qu'il existe une deuxième entrée de nom
prédéfini “.” qui
est associée au répertoire lui-même. Ainsi, après la
commande suivante qui définit le répertoire courant:
cd /developt/appl_graph/sources
le
fichier de nom absolu
/developt/appl_graph/sources/module1.c peut
être désigné simplement par
module1.c.
La notion de règles de recherche consiste à
définir une liste de noms absolus de répertoires qui sont
utilisés pour la recherche d'un objet dans un contexte particulier. Par
exemple, on définit couramment une liste de répertoire pour la
recherche du programme exécutable d'une commande, ce qui évite de
devoir se rappeler dans quel répertoire il est situé. De
même, on peut définir une liste de répertoire dans lequel il
faut rechercher les fichiers d'un manuel en ligne du système. Ces
règles de recherche peuvent être définies implicitement par
le système, et modifiables au gré de l'utilisateur qui peut ainsi
adapter son environnement à sa convenance.
9.5. Conclusion
+ La définition
d'une liaison doit permettre de localiser le support physique de l'objet, de
localiser l'objet sur le support et de déterminer les
caractéristiques de l'objet. Elle est donnée soit par le langage
de commande soit par les programmes.
+ Un volume est un
support d'informations. Pour être accessible il doit être
monté physiquement sur un périphérique et logiquement
reconnu par le système, c'est-à-dire que le système associe
ce périphérique à son nom.
+ Le formatage d'un
volume consiste à lui donner une structure qui comporte en particulier
son nom, la représentation de l'espace libre et les structures de
données nécessaires à la localisation des objets qu'il
contient.
+ Un répertoire
est une table qui associe un nom symbolique et le descripteur d'un objet
externe. Mémorisé sur un volume, il permet de localiser les objets
de ce volume. Lorsque le nombre d'objets est grand, on utilise une arborescence
de répertoire.
+ Le chemin
d'accès à un objet est la concaténation du nom de volume
sur lequel il se trouve et de la suite des noms dans les répertoires de
l'arborescence qui permet de l'atteindre.
+ Unix construit une
arborescence unique pour tous les objets, y compris les
périphériques, qui ont ainsi une désignation uniforme qui
permet à l'utilisateur de s'abstraire des
périphériques.
+ Les liens physiques
ou symboliques permettent de donner plusieurs noms absolus aux objets.
+ La
désignation peut être allégée en faisant
référence à l'environnement, au moyen de la notion de
répertoire de travail et de règles de recherche.