7
La notion de fichier
Nous avons vu dans les premiers chapitres que l'un des
rôles du système d'exploitation était de fournir à
l'utilisateur une machine virtuelle adaptée à ses besoins. Les
connexions avec les périphériques présentant des formes
variées, il est nécessaire d'étudier quels sont les vrais
besoins des utilisateurs pour réaliser cette adaptation.
Rappelons, tout d'abord, que nous avons distingué
quatre sortes de périphériques:
- les périphériques de dialogue
homme-machine, pour lesquels le transfert se fait caractère par
caractère, ou par écriture directe en mémoire pour les
écrans graphiques,
- les
périphériques de stockage séquentiel, pour lesquels le
transfert se fait par paquet de caractères, de taille
variable,
- les périphériques de
stockage aléatoire, pour lesquels le transfert se fait par paquet de
caractères, de taille fixe,
- les
périphériques de communication de machine à machine, pour
lesquels le transfert se fait par paquet de caractères, de taille
variable mais bornée, un protocole assez complexe étant
utilisé pour assurer ces
transferts.
7.1. Le but des objets externes
Rappelons que lors de l'exécution d'un programme, le
processeur ne manipule que des objets en mémoire centrale, dont les
caractéristiques générales imposent que de tels objets ne
puissent, en général, exister avant le chargement du programme, ou
après la fin de son exécution. Leur durée de vie est
limitée à la durée de présence du programme en
mémoire. On dit que ces objets sont internes au programme. Par
opposition, on appelle objet externe ceux qui ne sont pas
internes.
7.1.1. Les objets externes comme outils d'échange d'informations
On peut distinguer deux objectifs dans l'utilisation des
objets externes par un programme. Le premier est l'échange
d'informations, qu'il soit avec l'homme ou avec une autre machine. La
conséquence de cet échange est la nécessité de
trouver un langage commun entre les deux partenaires de
l'échange.
Avec l'homme comme partenaire, cela implique la transformation
de la représentation interne des données en une forme
compréhensible par l'homme, et réciproquement.
Lors de l'échange entre machines, plusieurs solutions
peuvent être adoptées, suivant la nature des machines qui
communiquent. Notons tout d'abord que l'échange de base est
réalisé sous forme d'une suite d'octets. À
l'émission, la représentation interne des données doit donc
être convertie en une suite d'octets, et l'opération inverse
effectuée à la réception. Les données
déjà sous forme de suite d'octets, comme par exemple les
chaînes de caractères, ne posent en général pas de
difficulté, du moins si les deux machines utilisent le même codage
des caractères (il en existe deux principaux:
EBCDIC et
ASCII). Les données dont la
représentation interne regroupe plusieurs octets posent plus de
difficultés.
- Lors du découpage d'un mot, deux ordres
des octets sont possibles. Certains constructeurs mettent d'abord les bits de
poids faibles, c'est-à-dire, ceux de droite en premier. D'autres font
l'inverse, c'est à dire mettent les bits de poids forts
d'abord.
- L'interprétation
sémantique de la représentation varie d'un constructeur à
l'autre, en particulier, pour les nombres flottants.
Si
les représentations des données sont les mêmes pour les deux
machines, en particulier si elles sont du même modèle, la
communication peut se faire en binaire, c'est-à-dire, dans la
représentation interne commune. Si ce n'est pas le cas, on peut faire,
sur l'une des machines ou sur l'autre, la conversion entre les
représentations binaires. Une dernière solution plus courante est
d'utiliser une représentation normalisée des données pour
assurer l'échange d'informations entre ces machines. L'avantage, dans ce
cas, est que le producteur de l'information n'a pas à se
préoccuper du destinataire, et réciproquement.
L'inconvénient est, bien entendu, la perte de temps machine qui
résulte de ces conversions.
Notons que cette conversion de données est
considérée comme suffisamment importante pour que certains
langages de programmation comme le COBOL permettent de les réduire au
minimum. Les données conservent alors dans le programme leur
représentation externe. La conversion éventuelle n'intervient
alors que lorsque les traitements le nécessitent. Le programmeur doit
évidemment avoir conscience du compromis qu'il doit choisir:
- Soit il convertit les données lors des
entrées-sorties, les rendant plus coûteuses, mais les traitements
sont efficaces car les opérations s'effectuent sur des données en
représentation interne.
- Soit il conserve
les données en mémoire sous leur forme externe, rendant les
entrées-sorties plus efficaces, mais les traitements sur les
données doivent les interpréter ou faire à chaque fois les
conversions correspondantes.
7.1.2. Les objets externes comme outils de mémorisation à long
terme
Un programmeur a aussi besoin des objets externes pour
disposer d'informations dont la durée de vie s'étend
au-delà de la durée de vie du programme. C'est le cas lorsque ces
données existent avant le chargement du programme, ou doivent être
conservées après la fin de son exécution.
Contrairement au cas précédent, c'est la
même machine qui crée ces données et les reprend
ultérieurement
[1]. On peut dire
effectivement qu'il s'agit encore de pouvoir échanger des informations
mais cette fois entre des programmes qui s'exécutent sur la même
installation. Le problème de conversion énoncé ci-dessus ne
se pose plus. Les données, en général, peuvent et doivent
être mémorisées dans leur représentation
interne.
Un problème peut cependant se poser pour les
données de type pointeur. Rappelons qu'un pointeur est une
information binaire qui permet de désigner un emplacement dans un espace
mémoire; c'est donc une adresse. Si cette mémoire est la
mémoire centrale, cela signifie que le pointeur désigne un objet
interne au programme, et n'a de signification que pour cette exécution.
Le conserver sous cette forme après la fin de l'exécution de ce
programme n'a pas sens. Sa valeur doit être remplacée par une
information qui désigne l'emplacement dans l'objet externe où sera
rangé la copie de la donnée interne pointée.
7.2. La manipulation des objets externes par le programme
Le mot fichier est parfois utilisé de façon
ambiguë, car il désigne tantôt l'objet externe
mémorisé sur un support magnétique (bande ou disque),
tantôt l'entité manipulée par le programme. Pour
éviter cette ambiguïté, le premier pourrait être
appelé fichier physique et le second fichier logique. En
général nous n'utiliserons le terme fichier que pour
désigner la façon dont le programme manipule l'objet
indépendamment de l'objet lui-même et des contraintes physiques
d'implantation comme des caractéristiques du périphérique
qui le supporte.
7.2.1. La notion de fichier
Le fichier est la façon dont un programme voit
un objet externe. C'est d'abord une collection d'enregistrements logiques
éventuellement structurée, sur laquelle le programme peut
exécuter un ensemble d'opérations. Un enregistrement logique,
encore appelé article, est l'ensemble minimum de données
qui peut être manipulé par une seule opération
élémentaire du fichier. Il est souvent constitué de
diverses données élémentaires, que l'on peut décrire
dans le langage de programmation utilisé, comme le montre la figure 7.1.
Ces données élémentaires ne sont accessibles
individuellement par le programme que lorsque l'enregistrement logique est
recopié dans un objet interne au programme. Dans cet exemple, le fichier
est constitué d'une collection d'enregistrements qui ont la structure
d'EMPLOYE. Les opérations sur le
fichier permettent de transférer le contenu d'un tel enregistrement entre
la mémoire interne du programme et l'objet externe qui lui est
associé.
01 EMPLOYE
02 NOM PICTURE X(30)
02 PRENOM PICTURE X(20)
02 NUM-S-S
03 SEXE PICTURE 9
03 DATE-NAISSANCE
04 ANNEE PICTURE 99
04 MOIS PICTURE 99
03 LIEU-NAISSANCE
04 DEPARTEMENT PICTURE 99
04 CANTON PICTURE 999
03 ORDRE PICTURE 999
02 CODE-INTERNE PICTURE 9999
Fig.
7.1. Exemple de description en COBOL d'un enregistrement
logique.
7.2.2. Le fichier séquentiel
La caractérisation des fichiers est
déterminée par la nature des opérations que l'on peut
effectuer sur le fichier. Le plus simple est le fichier séquentiel. Les
opérations se résument, essentiellement, en la lecture de
l'enregistrement suivant ou l'écriture d'un nouvel enregistrement en fin
du fichier séquentiel. Bien souvent, pour affirmer le caractère
séquentiel du fichier, il n'est pas possible de mélanger les
lectures et les écritures. Le fichier est alors un fichier
séquentiel en lecture ou un fichier séquentiel en
écriture.
Le fichier séquentiel en lecture est initialement
positionné sur le premier enregistrement logique. Chaque opération
de lecture (lire ou read) transfère dans une zone interne
au programme un enregistrement du fichier, et prépare le fichier pour le
positionner sur l'enregistrement suivant. On dispose souvent d'une
opération complémentaire qui permet de savoir s'il y a encore des
enregistrements à lire dans le fichier (fin_de_fichier ou
end_of_file), et éventuellement une opération permettant le
retour au début du fichier (rembobiner ou
rewind).
Le fichier séquentiel en écriture peut
être initialement vide, ou positionné après le dernier
enregistrement déjà dans le fichier. Chaque opération
d'écriture (ecrire ou write) rajoute un enregistrement dans
le fichier depuis une zone interne au programme, et positionne le fichier
après cet enregistrement. L'écriture d'un enregistrement se fait
donc toujours après ceux qui sont déjà dans le
fichier.
Noter que la caractéristique essentielle d'un fichier
séquentiel est que les enregistrements sont lus dans l'ordre où
ils ont été écrits. Aucune conversion des données
n'est appliquée, soit parce qu'elle est faite par le programme, soit
parce qu'elle n'est pas nécessaire.
7.2.3. Le fichier séquentiel de texte
Le fichier séquentiel de texte est analogue à un
fichier séquentiel, mais avec conversion du format des données
entre leur représentation interne et une représentation accessible
à l'être humain. L'expression des opérations
nécessitant la définition d'un format de conversion, la forme est
très dépendante du langage de programmation. On peut assimiler un
fichier séquentiel de texte à un fichier séquentiel
où les enregistrements logiques sont en fait des caractères
individuels.
En lecture, les opérations sur un tel fichier sont
complétées par des opérations qui permettent de lire une
donnée élémentaire, comme un entier, un nombre flottant,
etc..., par conversion d'une suite de caractères lus depuis le fichier,
suivant un certain format, implicite ou explicite.
En écriture, les opérations sur un tel fichier
sont complétées par des opérations qui permettent
d'écrire une donnée élémentaire, comme un entier, un
nombre flottant, etc..., par conversion en une suite de caractères
écrits dans le fichier, suivant un certain format, implicite ou
explicite.
Certains langages de programmation, comme le FORTRAN,
présentent le fichier séquentiel comme une collection
d'enregistrements logiques correspondant à une ligne de texte. En
lecture, on peut alors lire l'enregistrement complet, par le biais d'un format,
et d'un ensemble de variables élémentaires. Le format est alors
utilisé pour découper l'enregistrement en chaînes de
caractères et les convertir dans la représentation interne de ces
variables. De même, en écriture, on peut écrire un
enregistrement complet, par le biais d'un format et d'un ensemble de valeurs
élémentaires. Le format permet de convertir ces valeurs en leur
représentation externe et de les placer dans l'enregistrement.
7.2.4. Le fichier à accès aléatoire
Le but du fichier aléatoire est de permettre
l'accès à un enregistrement quelconque de la collection sans avoir
à parcourir tous ceux qui ont été écrits avant lui.
En général, il n'y a pas de restriction du type lecture seule ou
écriture seule, comme dans les fichiers séquentiels, mais au
contraire définition de trois opérations principales: lecture,
écriture et mise à jour d'un enregistrement après sa
lecture.
Pour fournir l'accès à l'un quelconque des
enregistrements, il faut que le programmeur puisse le désigner. Cette
désignation peut se faire par un numéro. Dans ce cas, le
fichier est vu comme une collection d'enregistrements numérotés.
Pour permettre d'implanter efficacement l'accès à un
enregistrement de numéro donné, la taille d'un enregistrement,
c'est-à-dire, le nombre d'octets de sa représentation, est en
général fixe. Pour le programmeur, le fichier à
accès aléatoire par numéro peut s'assimiler à un
tableau à une dimension. C'est évidemment lui qui fixe
l'attribution des numéros aux enregistrements lors des
écritures.
La désignation d'un enregistrement peut se faire par
l'intermédiaire d'une clé qui est en général incluse
dans l'enregistrement. Lors d'une lecture, le programmeur peut, par exemple,
donner d'abord une valeur aux champs correspondant à la clé dans
la zone mémoire interne de l'enregistrement, et en demander la lecture.
L'opération du fichier recherchera l'enregistrement correspondant et en
rangera la valeur dans la zone. L'opération de mise à jour
ou update, ultérieure réécrira cet enregistrement
sans avoir besoin de le rechercher de nouveau. Une opération
d'écriture, avec en paramètre le contenu de l'enregistrement dans
une zone en mémoire interne, consistera à placer l'enregistrement
dans l'objet externe, et à mettre à jour la structure de
données qui permet de le retrouver (fichier séquentiel
indexé ou B-arbre).
On trouve parfois un troisième type de fichier à
accès aléatoire construit sur un fichier séquentiel, mais
qui ne doit pas être confondu avec ce dernier. On dispose dans ce cas des
deux opérations de lecture séquentielle et d'écriture
séquentielle (au bout), ainsi que de deux opérations
supplémentaires permettant l'accès aléatoire aux
enregistrements du fichier:
- noter est une fonction qui retourne une
valeur binaire représentant la position de l'enregistrement courant dans
le fichier. Elle n'a de sens que pour le
fichier.
- positionner avec en
paramètre une valeur binaire précédemment obtenue par
l'opération noter ci-dessus, repositionne le fichier sur
l'enregistrement sur lequel il était au moment de cette
opération.
L'utilisation de ces opérations
permet au programmeur de construire des structures de données quelconques
sur un fichier. La valeur retournée par noter peut s'assimiler
à un pointeur externe et n'a de sens que sur le fichier dont il
provient.
7.3. La liaison entre le fichier et l'objet externe
7.3.1. L'établissement de la liaison
Un fichier (logique) peut être vu comme un objet interne
au programme. Pour pouvoir effectuer des opérations sur le fichier, il
faut qu'il soit relié à un objet externe. Il n'est pas
intéressant que cette liaison soit prise en compte par l'éditeur
de liens. En effet cela figerait cette liaison au moment de cette édition
de liens, le programme exécutable ne pouvant alors s'exécuter que
sur des objets externes définis à ce moment. Par ailleurs
l'éditeur de liens se préoccupe essentiellement des liaisons
internes au programme, alors qu'il s'agit de liaisons externes. Pour les
mêmes raisons, il n'est pas judicieux que la liaison soit fixée au
moment du chargement du programme. Au contraire elle peut être
établie et rompue dynamiquement au cours de son
exécution.
Nous reviendrons ultérieurement sur la
définition de cette liaison, qui doit permettre d'associer un fichier
interne au programme à un objet externe. En supposant que cette
définition existe, deux opérations sur un fichier quelconque
permettent d'exploiter cette définition:
- L'opération d'ouverture (on dit
aussi open) sur un fichier permet d'établir la liaison avec un
objet externe suivant les informations contenues dans sa
définition.
- L'opération de
fermeture (on dit aussi close) sur un fichier ouvert, permet de
rompre temporairement ou définitivement la liaison avec l'objet
externe.
Les opérations que nous avons
indiquées dans les paragraphes précédents ne peuvent
être appliquées que sur des fichiers ouverts, puisqu'elles ont pour
conséquence des accès à un objet externe qui doit donc
avoir été associé au fichier.
Il y a toutefois une exception à cette règle
d'établissement dynamique de la liaison. La plupart des systèmes
établissent trois liaisons spécifiques préalablement
à l'exécution du programme, pour les trois fichiers
standards:
- SYSIN pour
l'entrée des données provenant de l'utilisateur,
- SYSOUT pour la
sortie des données vers l'utilisateur,
- SYSERR pour la
sortie des messages d'erreurs vers l'utilisateur.
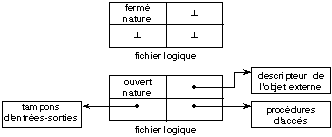
7.3.2. Représentation interne d'un fichier
La représentation interne d'un fichier logique dans le
programme est une structure de données (appelée parfois bloc de
contrôle de données ou encore Data Control Bloc). Elle
contient quatre types d'informations:
- Les attributs de la liaison permettent de
savoir quel est l'état de la liaison (ouverte ou fermée), les
variables internes de gestion de la liaison ainsi que les opérations
autorisées sur le fichier.
- Le
descripteur de l'objet externe permet de localiser l'objet externe. S'il
s'agit d'un périphérique, il faut connaître sa nature et son
adresse. S'il s'agit d'un fichier physique, il faut connaître en
plus la localisation de l'objet externe sur le périphérique qui le
supporte.
- Les procédures
d'accès sont en fait la concrétisation des opérations
du fichier sur l'objet externe qui lui est relié. Il faut noter que, vu
du programmeur, il s'agit toujours d'un ensemble d'opérations bien
définies, mais l'implantation proprement dite de ces opérations
dépend de la nature de l'objet externe et de son
support.
- Les tampons
d'entrées-sorties permettent d'assurer l'interface entre les
enregistrements logiques et les enregistrements physiques. Nous avons dit que
les opérations du fichier manipulaient des enregistrements logiques tels
que les définit le programmeur. Par contre les entrées-sorties
physiques ont des contraintes de taille et d'organisation qui dépendent
du support. Par exemple, sur un disque, les enregistrements physiques occupent
un nombre entier de secteurs. De même, sur une bande, les enregistrements
physiques doivent avoir une taille minimum si on veut avoir une bonne occupation
de l'espace. Les tampons permettent de regrouper plusieurs enregistrements
logiques par enregistrement physique lors des écritures, et de les
dégrouper lors de la lecture. Ils servent aussi à améliorer
les performances du transfert entre le support externe et la mémoire
centrale.
Certaines des informations
énoncées ci-dessus sont statiques, c'est-à-dire, connues
à la compilation. Ce sont celles qui sont directement liées
à la nature du fichier tel que l'utilise le programmeur. La plupart sont
en fait dynamiques, car elles dépendent du fichier et de l'objet externe
avec lequel il est relié. La figure 7.2 montre une telle
représentation d'un fichier logique lorsqu'il est ouvert ou
fermé.
Fig. 7.2. Représentation d'un
fichier ouvert ou fermé.
7.4. Conclusion
+ Les objets externes
peuvent être utilisés pour échanger des informations. Cet
échange peut nécessiter de convertir les données dans une
représentation commune.
+ Les objets externes
peuvent être utilisés pour mémoriser des données
à long terme. Aucune conversion n'est nécessaire sauf pour les
pointeurs vers la mémoire centrale qui perdent toute
signification.
+ Le fichier (logique)
est le point de vue qu'a un programme d'un objet externe. On distingue en
général le fichier séquentiel d'enregistrements, le fichier
séquentiel de texte, et le fichier à accès
aléatoire.
+ Un fichier doit
être relié à un objet externe pour pouvoir être
utilisé. La liaison est établie par l'ouverture, et
supprimée par la fermeture.
+ En mémoire
centrale, un fichier logique est représenté par une structure de
données (DCB) qui contient les attributs de la liaison, le descripteur de
l'objet externe, les procédures d'accès et les tampons
d'entrées-sorties.
[1] au moins dans le cas des
systèmes centralisés. Dans un réseau local, avec un serveur
de fichier, ce peut être une autre machine.