6
Autres outils de la chaîne de production
Nous allons étudier ici quelques uns des autres outils
qui participent à la chaîne de production des programmes. Ils ne
sont pas aussi indispensables que les traducteurs, l'éditeur de liens ou
le chargeur, mais ils facilitent grandement le travail du programmeur lorsqu'ils
sont disponibles. Leur présence sur un système particulier
dépend du bon vouloir du constructeur de la machine, ou plus souvent, de
la reconnaissance de leur intérêt en fonction des
applications.
6.1. Les outils d'aide à la mise au point
6.1.1. La notion de trace
La mise au point d'un programme est en général
une tâche difficile, et diverses méthodes ont été
proposées pour aider le programmeur dans cette tâche. La
première, et la plus simple, a été de lui permettre de
suivre l'évolution de l'état du programme au cours du temps, c'est
ce que l'on, appelle la trace du programme. Pratiquement, il n'est pas
possible de suivre cette évolution sur l'état complet du
programme. Il est nécessaire de restreindre ce suivi sur une petite
partie de cet état. Les principales informations utiles sont les
suivantes:
- tracer les appels de sous-programmes avec les
paramètres correspondants, et leurs retours avec la valeur du
résultat,
- tracer le déroulement des
instructions, en particulier pour reconnaître les ruptures de
séquences,
- tracer les valeurs prises
successivement par des variables,
- connaître
l'état des données en certains points précis du
programme.
L'obtention de ces traces peut être
définie en introduisant dans les modules sources des instructions
spéciales qui sont ou non prises en compte par le traducteur en fonction
d'options décidées lors de la demande de traduction. C'est alors
le traducteur qui insère dans le module objet des instructions, en
général d'impression, qui permettent de suivre le
déroulement de l'exécution.
La difficulté essentielle de cette méthode est
qu'il faut prévoir ces options au moment de la traduction du module. Il
est possible que lors de l'analyse du résultat de l'exécution, il
soit nécessaire de connaître d'autres informations pour
déterminer l'erreur. Il faut alors refaire la traduction du module en
adaptant les options de mise au point en conséquence. Pour éviter
cela, la tendance est de prendre le maximum d'options, mais alors il faut
dépouiller une quantité importante d'informations pour trouver
celles qui sont effectivement utiles.
L'introduction des instructions de trace par l'éditeur
de liens lui-même, ou par le chargeur, a été très peu
utilisée, car ce n'est pas d'un emploi commode.
6.1.2. La notion de point d'arrêt, de reprise et de pas à pas
L'inconvénient majeur des options de traces
traitées par le traducteur est le manque de souplesse pendant
l'exécution. Lors de la recherche d'une erreur, il est souvent
nécessaire de disposer de beaucoup d'informations sur l'évolution
de l'état du programme au voisinage de l'endroit où se produit
cette erreur. Pour faciliter le suivi de cette évolution, il suffit de
pouvoir arrêter temporairement cette exécution, pour permettre
l'observation de l'état complet du programme. Ceci est obtenu par le
biais de points d'arrêt, qui sont des adresses d'emplacements
particuliers du programme où on désire que l'exécution soit
interrompue, avant que l'une des instructions situées à ces
emplacements ne soit exécutée.
Lorsqu'un programme est ainsi interrompu en un point
d'arrêt, le programmeur doit avoir le moyen de consulter l'état du
programme, en regardant le contenu de l'espace mémoire qu'il occupe. Il
doit pouvoir éventuellement modifier (à ses risques et
périls) le contenu de cet espace mémoire, pour en corriger
certaines valeurs. Il doit pouvoir également en reprendre
l'exécution, ce que l'on appelle la reprise. On appelle metteur
au point ou débogueur (en Anglais debugger) un outil
interactif qui permet de créer des points d'arrêt dans un programme
pour en consulter ou modifier le contenu mémoire et en reprendre ensuite
l'exécution.
Le pas à pas est un cas particulier du couple
<point d'arrêt, reprise>, puisqu'il s'agit, sur un programme
interrompu, d'en reprendre l'exécution pour une instruction avant de
l'arrêter de nouveau. Ce pas à pas peut être au niveau
machine, c'est-à-dire que la reprise n'a lieu que pour exécuter
une seule instruction de la machine. Pour un programmeur en langage
évolué, ceci n'est guère agréable, car il n'a
souvent que peu de connaissance des relations entre les instructions de la
machine et les instructions en langage évolué. C'est pourquoi, on
lui préfère le pas à pas au niveau langage
évolué. Cependant, il faut alors que le metteur au point ait une
connaissance du découpage de la suite des instructions machines en
instructions en langage évolué.
6.1.3. Les metteurs au point symboliques
La définition d'un point d'arrêt doit localiser
un emplacement particulier de l'espace mémoire du programme. La
consultation de l'état du programme demande également de localiser
les emplacements dont on veut connaître ou modifier la valeur. Cette
localisation peut évidemment être donnée par une valeur
numérique dans une base adaptée, octal, décimal,
hexadécimal, etc... Cela demande au programmeur de connaître ces
valeurs numériques. Ce sont en fait des valeurs connues de façon
dispersée par les traducteurs, l'éditeur de liens et le chargeur.
Pour le programmeur, elles correspondent à des identificateurs de ses
modules sources. Une coopération entre l'ensemble permet d'exprimer ces
adresses par les identificateurs eux-mêmes. C'est ce que l'on appelle un
metteur au point symbolique.
Pour permettre cette localisation, le traducteur doit tout
d'abord compléter le module objet qu'il produit par une table de
symboles, qui associe aux identificateurs internes aux modules (en plus des
liens) les adresses relatives des emplacements attribués aux objets
correspondants. Cette table a la même signification que les liens
utilisables du module. L'éditeur de liens n'utilise pas cette table, si
ce n'est pour translater les adresses pour les rendre relatives au programme
exécutable et non plus au module objet. Cette table associe
également à chaque identificateur des informations sur le type de
l'objet, pour permettre au metteur au point d'éditer (ou saisir) les
valeurs des objets conformément à leur type. Cela permet aussi
d'accéder aux champs d'une structure par la notation pointée
habituelle aux langages de haut niveau.
Le traducteur produit enfin une deuxième table qui
associe aux numéros de lignes contenant des instructions du langage de
haut niveau, l'adresse relative de la première instruction en langage
machine correspondant. Après translation des valeurs de cette table par
l'éditeur de liens, il sera ainsi possible de définir les points
d'arrêt ou le pas à pas en terme d'instructions de haut niveau,
clairement identifiées par le programmeur.
Le traducteur, puis l'éditeur de liens, mettra les
informations nécessaires à l'identification du module source. Le
metteur au point pourra ainsi lister les lignes du texte source à la
demande de l'utilisateur, lui permettant de contrôler effectivement
où il en est dans le programme.
Disposant de toutes ces informations dans le fichier du
programme exécutable, le metteur au point peut offrir les
opérations suivantes à l'utilisateur:
- Possibilités de trace. Il est possible de mettre en route ou
d'arrêter à tout instant des options de trace comme
indiquées ci-dessus.
- Consultation et modification des variables du
programme. Ceci permet éventuellement de corriger des valeurs
erronnées et poursuivre la mise au point sans être obligé de
corriger le texte source et le recompiler.
- Création et suppression
de points d'arrêt. On peut ainsi lancer des parties d'exécution
longues et s'arrêter aux endroits où l'on désire effectuer
des contrôles plus précis.
- Exécution en pas à
pas. Elle permet de contrôler plus finement le comportement du
programme à certains endroits.
- Consultation des appels de
procédure en cours. Lorsqu'un programme est interrompu, on peut ainsi
savoir si on est dans le programme principal ou dans une procédure, et
dans ce dernier cas, quels sont les appels imbriqués depuis le programme
principal qui ont conduit à la procédure courante.
- Lister
le fichier source. En particulier on peut ainsi savoir quelles sont les
instructions de haut niveau qui seront exécutées à la
reprise.
- Éditer le texte source. Le metteur au point peut
permettre de faire appel à l'éditeur de texte pour porter des
corrections au fur et à mesure dans les modules sources, et poursuivre
ensuite la mise au point. Évidemment, ceci ne modifie pas le programme
exécutable, les modules ainsi modifiés devant être
recompilés, et l'édition de liens refaite, mais permet d'avoir un
“aide-mémoire” des corrections à
apporter.
Les metteurs au point offrent toujours au moins
les quatre premières opérations. S'ils sont simples (on dira
parfois qu'ils sont binaires), ils ne connaissent que l'organisation de
la machine physique, et ne prennent pas en compte le langage d'écriture
des modules qui constituent le programme. Éventuellement ils sont
dotés d'un désassembleur qui permet de lister les
instructions de la machine sous forme mnémonique. Ils peuvent aussi
exploiter une table des symboles dans le programme exécutable,
évitant à l'utilisateur de devoir définir des adresses
uniquement sous forme numérique. Les metteurs au point symboliques par
contre exploitent un minimum d'informations provenant du langage de haut niveau
utilisé pour écrire les modules. C'est pourquoi, ils peuvent
prendre en compte les structures principales de ces langages pour les quatre
premières fonctions et fournir les trois fonctions
supplémentaires.
6.1.4. Les metteurs au point symboliques multi-fenêtres
Lorsqu'on dispose d'un système multi-fenêtres,
permettant de découper l'écran en plusieurs zones distinctes, les
metteurs au point symboliques peuvent en tenir compte pour faciliter le travail
de l'utilisateur. Trois fenêtres sont alors le plus souvent
utilisées:
- fenêtre des variables, où le
metteur au point affiche les valeurs des variables dont la consultation ou la
trace sont demandées,
- fenêtre de
commandes, qui sert à l'échange des commandes de l'utilisateur au
metteur au point,
- fenêtre de source,
où le metteur au point affiche en permanence les quelques lignes du
module source qui entourent le point d'arrêt sur lequel on
est.
La manipulation du metteur au point par l'utilisateur
en est alors grandement facilitée, puisque certaines commandes sont
implicites et qu'il a devant les yeux les informations essentielles pour cette
mise au point.
6.1.5. Les mesures de comportement dynamique
Certains systèmes offrent la possibilité de
faire des mesures sur le comportement dynamique d'un programme à
l'exécution. En général, deux types de mesures sont
possibles:
- compter le nombre de fois où chaque
instruction ou suite d'instructions est
exécutée,
- mesurer le temps
passé, à l'exécution, dans chaque instruction ou suite
d'instructions du programme.
Ces mesures peuvent
être effectuées sur la totalité du programme, ou sur
certains modules spécifiques. Elles sont obtenues, au moyen d'une option
de traduction, qui demande au traducteur d'introduire des instructions aux
endroits judicieux du programme. Par exemple, l'incrémentation d'un
compteur avant l'exécution d'une instruction en langage
évolué permet de compter le nombre de ses exécutions;
l'appel à une fonction système spécifique permet d'obtenir
les mesures de temps d'exécution. Ces mesures peuvent être plus ou
moins précises, suivant les caractéristiques du matériel.
Les résultats sont mémorisés dans un fichier, au fur et
à mesure, et peuvent être exploités par un outil
spécifique qui rattache les mesures aux instructions des modules sources
correspondants.
Multics permet de faire ces mesures au niveau de chaque
instruction des langages évolués, grâce à une horloge
très précise (de l'ordre de la microseconde). Mais on les trouve
plus souvent au niveau des appels de sous-programmes, car la durée
d'exécution plus importante exige une précision moins grande des
mesures de durées.
L'intérêt de ces mesures réside surtout
dans l'amélioration ultérieure de l'efficacité du programme
par l'utilisateur, qui sait alors exactement où il doit porter son
effort. Il est, en effet, inutile de gagner quelques microsecondes sur une
instruction qui est exécutée une seule fois, alors que l'on peut
être surpris de la durée effective d'une instruction banale, mais
qui fait intervenir des conversions coûteuses.
6.2. Les préprocesseurs et les macrogénérateurs
Il arrive souvent que l'on ait besoin de disposer d'un module
source sous différentes versions assez proches les unes des autres, sans
que la fonctionnalité et les spécifications du module soient
changées. C'est le cas, par exemple, lorsque le module utilise des
constantes d'adaptation qui permettent de configurer les tailles des zones de
données internes. C'est le cas également lorsque le module est
intégré à une application qui doit pouvoir être
portée sur des machines et systèmes différents,
entraînant des variantes mineures de ce module. Si on dispose d'autant de
copies de ce module source qu'il y a de versions, on rencontre deux
problèmes: le premier est le nombre de ces copies presque identiques, et
le second est la maintenance de toutes ces copies, lorsqu'une modification doit
être apportée à toutes les versions.
Certains langages de programmation, ou leur traducteur,
intègrent la prise en compte de ces différentes versions.
Cependant une autre solution consiste à disposer d'un seul exemplaire du
module source qui est alors paramétré pour permettre la
construction d'une version particulière immédiatement avant la
traduction. C'est le rôle d'un programme spécifique appellé
préprocesseur. L'intérêt de reporter au niveau d'un
préprocesseur ce travail, au lieu de le laisser au traducteur, est que,
d'une part, le préprocesseur n'est pas attaché à un langage
particulier, et peut donc servir à beaucoup de langages, d'autre part,
cela simplifie le traducteur.
Nous allons nous baser sur le préprocesseur construit
par les concepteurs du langage C, pour expliquer succintement le fonctionnement
général. L'idée est qu'un préprocesseur prend en
entrée un module source, et fournit en sortie un module source
transformé. Il s'agit donc bien d'un outil qui travaille au niveau texte
source. Il doit être capable de distinguer dans ce texte source les
commandes qui lui sont destinées du reste du texte. Dans le cas du
préprocesseur de C, on les distingue par la présence du
caractère "#" en début de
ligne. Ces commandes doivent permettre des modifications simples du reste du
texte. En voici les principales:
#include "nom de fichier" |
demande au préprocesseur d'inclure à cet endroit
le fichier correspondant.
|
#define TOTO 2456 |
demande au préprocesseur de remplacer
systématiquement, à partir de maintenant la chaîne de
caractères TOTO par
2456 partout où elle se
trouve.
|
#undef TOTO |
demande au préprocesseur d'arrêter le
remplacement systématique de la chaîne
TOTO.
|
#ifdef TOTO
°°°
#else
°°°
#endif |
demande au préprocesseur de transmettre les lignes qui
suivent la commande #ifdef, s'il y a une
demande de remplacement en cours pour la chaîne
TOTO, et de les supprimer s'il n'y en a
pas. La prochaine commande #else, si elle
existe, entraînera l'action opposée (suppression ou transmission)
pour les lignes qui suivent, et la commande
#endif reprendra le cours de fonctionnement
normal. Ces commandes peuvent être imbriquées, avec la
signification habituelle des langages de haut niveau.
|
Il faut remarquer que le langage de définition des
commandes ainsi que les opérations de remplacement dans le texte
n'impliquent aucune relation avec le langage C lui-même. Ce
préprocesseur est d'ailleurs communément utilisé pour le
langage Pascal dans les systèmes Unix.
Les remplacements définis ci-dessus sont rudimentaires.
En fait ils peuvent être paramétrés. Ainsi la
commande
#define NUMERO(A, B) 25 * A + B
demande
le remplacement des chaînes de la forme NUMERO
(u, v), où u et
v sont des chaînes quelconques ne
contenant pas de virgules, par la chaîne 25 * u +
v. On dit parfois que l'on a une macrodéfinition. Il
est important de rappeler que le préprocesseur travaille au niveau
chaîne de caractères, sans avoir de connaissance du langage
représenté. C'est à l'utilisateur de prendre garde que la
chaîne obtenue après remplacement soit conforme à ce qu'il
désire. Par exemple, dans le contexte de la commande
précédente,
NUMERO(x + 1, y) deviendra 25 * x + 1 + y
NUMERO((x + 1), y) deviendra 25 * (x + 1) + y
Il
est probable que le premier remplacement n'est pas celui désiré.
Il serait en fait préférable d'écrire:
#define NUMERO(A, B) 25 * (A) + (B)
pour
que l'interprétation du remplacement obtenu conserve la structure
syntaxique 25 * A + B, quels que soient
A et
B.
Plus généralement on parlera de
macrogénérateur pour un outil qui a pour but de produire un
module source dans un langage de programmation donné, à partir
d'un module source qui mélange des commandes dans le langage du
macrogénérateur, parfois appellé
méta-langage, et des parties dans ce langage de programmation.
L'une des utilisations les plus courantes est de faciliter l'interfaçage
d'un programme d'application avec une base de données. Le programmeur
exprimera ses requêtes à la base de données dans le
méta-langage, le macrogénérateur traduira ces
requêtes en une suite d'instructions du langage de programmation, souvent
constituées d'appels à des sous-programmes
spécifiques.
6.3. Le make
Nous avons vu qu'un programme était constitué de
plusieurs modules. Mais chacun de ces modules peut lui-même servir
à construire plusieurs programmes. Lorsque le nombre de modules
impliqués dans un ensemble de programmes est important, il devient
difficile de maîtriser complètement les conséquences d'une
modification d'un module particulier sur les programmes exécutables. Plus
généralement, le problème est d'être certain que les
programmes exécutables reflètent bien toutes les modifications qui
ont été apportées dans les modules sources. Une solution
est évidemment de refaire la traduction de tous les modules, et de
refaire ensuite l'édition de liens de tous les programmes. Ceci peut
entraîner des traductions inutiles, et des éditions de liens
inutiles. Le make est un programme qui résout ce problème
en ne faisant que ce qui est nécessaire, sous réserve que les
informations qu'il exploite soient cohérentes. Initialement écrit
pour le système Unix, de nombreuses versions existent maintenant pour des
systèmes variés.
6.3.1. Graphe de dépendance
Pour déterminer ce qui doit être fait,
make utilise trois sources d'informations:
- un fichier de description, appellé
makefile, construit par l'utilisateur,
- les
noms et les dates des dernières modifications des
fichiers,
- des règles implicites
liées aux suffixes des noms de fichiers.
À
partir de ces informations, il construit d'abord un graphe de
dépendance sur l'ensemble des fichiers qui servent à la
construction du fichier cible que l'on cherche à obtenir, et qui est
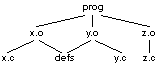
fourni en paramètre à make. Considérons par exemple
un programme exécutable appellé
prog, obtenu par édition de liens
des modules objets situés dans les fichiers
x.o,
y.o et
z.o. On dit que
prog dépend de ces fichiers. De
même, si le module objet x.o est
obtenu par compilation d'un module source situé dans le fichier
x.c, avec inclusion du fichier source
defs, on dit que
x.o dépend de
x.c et de
defs. Remarquons que la compilation de
x.c demandant l'inclusion de
defs n'entraîne pas de
dépendance entre x.c et
defs, puisque
x.c n'est pas construit à partir de
defs. Par contre, il y a bien
dépendance de x.o sur
defs, puisqu'une modification de
defs nécessite de reconstruire
x.o. La figure 6.1 représente le
graphe de dépendance complet.
Fig. 6.1. Graphe de
dépendance.
Les dépendances peuvent être directement
décrites dans le fichier makefile, et c'est un de ses rôles.
On pourrait ainsi mettre dans ce fichier les lignes suivantes:
prog : x.o y.o z.o
x.o y.o : defs
Certaines
dépendances peuvent être aussi obtenues au moyen de règles
implicites simples et naturelles. Prenons comme convention (c'est assez
habituel, et nous l'avons déjà fait), que les modules objets,
résultats d'une traduction, sont dans des fichiers dont le nom est le nom
du module suffixé par .o; ces
fichiers dépendent évidemment du fichier qui contient le module
source. Il est naturel, et également courant, de donner au fichier source
le nom du module avec un suffixe lié au langage dans lequel il est
écrit, comme par exemple .c pour le
langage C, .p pour la langage pascal, ou
.f pour le Fortran. Make peut alors
chercher à utiliser les noms des fichiers du répertoire courant
pour compléter les règles de dépendances. Ainsi, pour le
fichier x.o, il recherche dans le
répertoire un fichier dont le nom commence par
x et suffixé par l'un de ceux
correspondant à un langage source. Le fait de trouver le fichier
x.c, lui permet d'établir la
dépendance correspondante.
6.3.2. Exploitation du graphe de dépendance
Pour déterminer si un fichier est à jour,
c'est-à-dire reflète les dernières modifications, il suffit
de contrôler que chaque fichier existe et a une date de dernière
modification supérieure ou égale à celle des fichiers dont
il dépend. Si c'est le cas pour tous les fichiers du graphe, rien n'est
à faire, et le fichier cible est à jour. Si ce n'est pas le cas,
il est nécessaire de reconstruire ceux qui ne vérifient pas cette
propriété. Il est nécessaire de faire cette reconstruction
depuis le bas du graphe en remontant vers le haut, puisque la reconstruction
d'un fichier entraîne celle de tous ceux qui dépendent de lui et
qui sont donc situés au dessus.
Le problème est alors de savoir comment on peut
reconstruire un fichier à partir de ceux dont il dépend. Pour
cela, il est possible d'attacher à une règle de dépendance
dans le fichier makefile un ensemble de commandes dont l'exécution
sera demandée au système par make lorsque la règle
ne sera pas respectée. De même, aux règles implicites sont
attachées une ou plusieurs commandes qui jouent le même rôle.
Pour notre exemple, le fichier makefile pourrait associer à la
règle relative à prog la
commande d'appel de l'édition de liens avec l'utilisation de la
bibliothèque de nom s, et dont le
résultat serait mis dans le fichier
prog:
prog : x.o y.o z.o
ld x.o y.o z.o -ls -o prog
x.o y.o : defs
La
commande associée à la règle implicite de dépendance
du suffixe .o sur
.c pourrait être l'appel du
traducteur correspondant sur le fichier source.
6.3.3. Macro substitution
Pour faciliter l'écriture du fichier makefile,
make propose un mécanisme simple de macro substitution. Une
définition de macro est simplement une ligne contenant un nom suivi du
signe "=" et du reste de la ligne. Une
référence à une macro est constituée du signe
"$" suivi du nom de la macro entre
parenthèses s'il fait plus d'un caractère. Par ailleurs, avant de
lancer des commandes relatives à une règle de dépendance,
make initialise certaines macros, comme par exemple
$? qui représente la chaîne
des noms de fichiers qui ont été trouvés plus
récents que le fichier cible, et qui sont donc la cause de cette
exécution.
Dans le contexte du fichier makefile de la figure 6.2,
l'exécution de
make prog
entraîne
la construction du graphe de dépendance donné en figure 6.1, et
les recompilations éventuellement nécessaires ainsi que
l'édition de liens. Le nom de l'éditeur de liens est
paramétré par $(LD),
implicitement identifié à ld,
pour permettre sa redéfinition lors de l'appel de make. De
même, la définition des bibliothèques utilisées lors
de cette édition de liens est paramétrée explicitement par
la définition de la macro
LIBES.
OBJECTS = x.o y.o z.o
FILES = x.c y.c z.c defs
LIBES = -ls
P = imprint -Plplaser
prog : $(OBJECTS)
$(LD) $(OBJECTS) $(LIBES) -o prog
x.o y.o : defs
print : $(FILES)
$P $?
touch print
arch :
ar uv /usr/src/prog.a $(FILES)
Fig.
6.2. Exemple de fichier makefile.
Pour dater certaines opérations, il est possible de
créer des fichiers vides, et de demander au système de modifier la
date de leur dernière modification lorsque l'opération est
exécutée (commande touch avec
Unix, par exemple). Supposons qu'il existe un tel fichier de nom
print, dans le contexte du même
fichier makefile, l'exécution de
make print
entraînera
l'impression des fichiers qui sont plus récents que ce fichier. Les
commandes associées à la règle de dépendance non
seulement impriment ceux qui sont plus récents, mais force la date du
fichier print pour mémoriser la date
à laquelle cette opération a été faite.
Enfin, après construction du graphe de
dépendance, si un fichier n'existe pas, le make exécute les
commandes associées à la règle de dépendances qui
lui correspond. En général, ces commandes entraînent sa
construction effective. Cependant, si le fichier n'est pas créé,
le make considère qu'il a la date actuelle vis-à-vis des
règles de dépendances au-dessus de lui. Il n'est donc pas
obligatoire qu'un fichier soit effectivement attaché aux
opérations. Ainsi, dans le contexte de l'exemple, l'exécution
de
make arch
entraîne
toujours l'exécution des commandes associées, puisque le fichier
arch n'existe pas. Lorsque la commande est
exécutée, le fichier n'est toujours pas créé, mais
make considère qu'il est daté du moment présent, et
donc que les propriétés d'antériorité sont
respectées.
6.4. Les outils complémentaires
Il est courant de trouver sur la plupart des installations,
des outils d'aide à la gestion des modules.
Ce peut être, par exemple, un archiveur qui
permet d'archiver des modules sources, ou plus généralement des
fichiers quelconques. Leur intérêt est d'une part de regrouper
ensemble des fichiers qui forment un tout cohérent, d'autre part de
diminuer l'encombrement sur support secondaire de cet ensemble, par le biais de
techniques complexes de compression d'informations. Le résultat est
souvent au moins deux fois moins encombrant.
Pour faciliter le suivi de l'évolution d'un module
source, on peut disposer d'un programme, appellé diff, qui
détermine la différence entre deux fichiers de texte. Le
résultat est la suite de commandes d'édition qui permet à
un éditeur orienté lignes, de reconstruire le deuxième
fichier à partir du premier. On voit que ceci permet à un
programmeur de diffuser les modifications à apporter à une version
du source pour passer à la version suivante. Celui qui reçoit le
résultat du diff, n'a pas à faire les modifications
à la main, mais à les faire exécuter par l'éditeur
orienté lignes correspondant.
La présentation externe d'un module source est souvent
très importante pour la mise au point et la maintenance. Un
paragrapheur, encore appellé indenteur, est un programme
qui donne une forme standard à un fichier source écrit dans un
langage donné. Il est adapté au langage lui-même, car cette
forme ne peut être obtenue que par une analyse lexicale et surtout
syntaxique du texte source, pour en reconnaître les structures
fondamentales.
La gestion des modules objets et des bibliothèques de
ces modules est souvent assurée par un bibliothéquaire.
Nous avons vu qu'une telle biblothèque de modules pouvait
nécessiter une structure de données pour rendre plus efficace le
travail de l'éditeur de liens.
De nombreux autres outils existent. Nous ne pouvons les
décrire tous, certains étant dédiés à des
tâches très précises. La raison est que souvent lorsque l'on
doit faire ponctuellement une activité automatisable, il est
préférable de faire l'outil qui réalisera cette
activité plutôt que de faire l'activité soi-même, car
l'outil pourra resservir.
6.5. Conclusion
+ La trace d'un
programme est une suite d'informations qui permettent de contrôler
l'évolution de l'état d'un programme au cours de son
exécution. En fait on ne cherche bien souvent à connaître
qu'une partie de cette trace.
+ Un point
d'arrêt dans un programme est un endroit où l'on désire
arrêter l'exécution du programme pour consulter son état
interne. La reprise est la possibilité de poursuivre l'exécution
du programme après qu'il ait été interrompu. Le pas
à pas est la possibilité d'exécuter le programme une
instruction à la fois.
+ Un metteur au point
est un outil qui permet de contrôler interactivement l'exécution
d'un programme. Il est symbolique lorsqu'il permet l'expression des commandes en
utilisant les structures du langage évolué dans lequel le
programme a été écrit.
+ Les mesures de
comportement dynamique d'un programme permettent de savoir où il faut
porter son effort pour améliorer son temps d'exécution.
+ Un
préprocesseur ou un macrogénérateur est un programme qui
permet de faire un traitement simple sur le texte source avant de le donner
à un traducteur.
+ Il existe un graphe
de dépendance entre l'ensemble des fichiers utilisés dans la
chaîne de production de programmes: un fichier
A dépend d'un fichier
B si B
est utilisé pour construire
A.
+ Un fichier contenant
un programme exécutable est à jour si pour tous les fichiers
A et B
de son graphe de dépendance, tels que
A dépende de
B, la date de dernière modification
de A est postérieure à celle
de B.
+ Le make est
un outil qui, à l'aide d'un fichier parmètre, construit le graphe
de dépendance d'un programme exécutable, contrôle qu'il est
à jour et exécute les commandes minimales pour assurer cette mise
à jour, si ce n'est pas le cas.
+ Le make peut
être utilisé chaque fois qu'il existe un graphe de
dépendance entre des fichiers, pour contrôler que ces fichiers sont
à jour, et exécuter les commandes nécessaires à
cette mise à jour, si ce n'est pas le cas.
+ Beaucoup d'autres
outils existent, car il est souvent préférable de faire un outil
pour une activité automatisable, plutôt que de réaliser
l'activité à la main.