5
L'édition de liens et le chargement
Les programmes relativement complexes ne peuvent être
écrits est nécessaire de pouvoir les découper en morceaux,
chacun d'eux pouvant alors être modifié, compilé et
testé séparément des autres. Les morceaux doivent ensuite
pouvoir être rassemblés pour former le programme complet. Nous
avons appelé module source un tel morceau de programme pouvant
être traité de façon indépendante par un traducteur,
et module objet le résultat de cette traduction. Nous nous
intéressons maintenant à la reconstruction du programme complet
à partir des modules objets. Nous avons appelé édition
de liens cette opération. Elle est réalisée par un
programme spécifique, appelé éditeur de liens (en
Anglais link editor).
Pour préciser clairement ce dont on parle, on utilise
parfois le terme module éditable ou programme
éditable pour désigner le résultat d'une traduction qui
nécessite le passage par l'édition de liens, et le terme
programme exécutable pour désigner un programme complet
prêt à être chargé et exécuté.
5.1. La notion de module translatable
Un module objet, lorsqu'il est inclus dans un programme
exécutable, occupe un certain nombre d'emplacements en mémoire.
Ces emplacements doivent être disjoints de ceux occupés par les
autres modules objets du même programme. L'architecture matérielle
(par exemple, Multics, iAPX432, etc...) permet parfois de conserver la
modularité à l'exécution en attribuant des espaces
mémoires disjoints à chaque module. Les adresses sont alors des
couples <n, d> où
n désigne l'espace attribué
au module, et d un déplacement
relatif dans cet espace. Dans ce cas, le traducteur est entièrement
maître de la gestion interne, dans cet espace, des objets appartenant au
module qu'il traite, et donc des valeurs des déplacements
relatifs.
Par contre, dans la majorité des cas, il faut pouvoir
mettre dans un espace unique plusieurs modules issus de traductions
différentes. Les traducteurs doivent alors mettre dans les modules
éditables qu'ils produisent les informations qui permettent de placer ces
modules n'importe où en mémoire. En principe, il suffit qu'ils
indiquent les différents emplacements où sont rangées des
adresses internes au module. En fait, les traducteurs séparent souvent
l'espace mémoire du module en plusieurs sections suivant la nature
de leur contenu, comme par exemple:
- code des
instructions,
- données
constantes,
- données
variables.
Ces différentes sections,
gérées séparément par le traducteur peuvent
être mises n'importe où en mémoire. Les informations de
placement produites par le traducteur précisent alors pour chaque
emplacement qui contient une adresse, la section à laquelle cette adresse
se réfère. On dit alors que le module objet est
translatable. L'opération de translation consiste à ajouter
à chacun des emplacements qui contient une adresse, la valeur de
l'adresse effective d'implantation finale de la section.
Considérons, comme exemple, le petit programme suivant
en assembleur 68000, dont la traduction en hexadécimal est donnée
à côté, ( à droite du
:) après l'adresse relative du
premier octet dans la section (à gauche du
:). Deux instructions, la deuxième
et la cinquième font référence à un emplacement
mémoire: l'adresse générée sur 4 octets a
été soulignée. La première est relative à
l'identificateur C qui repère une
instruction, dont l'emplacement est à l'adresse relative
0E dans la section du code des
instructions. La seconde est relative à l'identificateur
MEMO qui repère une donnée,
dont l'emplacement est à l'adresse
02 dans la section des données
variables.
AJOUT10: move.w #10,D0 0 : 30 3C 00 0A
jmp C 4 : 4E F9 00 00 00 0E
AJOUT16: move.w #16,D0 A : 30 3C 00 10
C: add.w D1,D0 E : D1 01
move.w D0,MEMO 10 : 33 C0 00 00 00 02
rts 16 : 2E 75
.data
LOC: ds.w 1 0 : 00 00
MEMO: ds.w 1 2 : 00 00
.end
informations de translation:
en 6 section code, adresse 4 octets relative au code
en 12 section code, adresse 4 octets relative aux données
Si
l'éditeur de liens décide de mettre la section de code à
l'adresse hexadécimale 012340, et la
section des données à l'adresse hexadécimale
023220, le module doit être
modifié en conséquence. A l'adresse relative
6 de la section de code, il faut ajouter
l'adresse de début de la section de code, donc
012340, (sur 4 octets), et à
l'adresse relative 012 de la section de
code, il faut ajouter l'adresse de début de la section des
données, donc 023220. On obtient
alors le code suivant, où nous laissons figurer le texte assembleur pour
permettre au lecteur de comparer avec ce qui précède.
AJOUT10: move.w #10,D0 012340 : 30 3C 00 0A
jmp C 012344 : 4E F9 00 01 23 4E
AJOUT16: move.w #16,D0 01234A : 30 3C 00 10
C: add.w D1,D0 01234E : D1 01
move.w D0,MEMO 012350 : 33 C0 00 02 33 22
rts 012356 : 2E 75
.data
LOC: ds.w 1 023320 : 00 00
MEMO: ds.w 1 023322 : 00 00
.end
5.2. La notion de lien
La construction d'un programme à partir d'un ensemble
de modules n'est pas simplement la juxtaposition en mémoire de l'ensemble
de ces modules. Il est nécessaire d'assurer une certaine forme de
coopération entre les modules, et donc qu'ils puissent communiquer. Cette
communication peut se faire par variable globale, c'est-à-dire
qu'une variable appartenant à un module est accessible depuis un ou
plusieurs autres modules. Elle peut se faire par appel de
procédure, c'est-à-dire qu'une procédure ou une
fonction appartenant à un module est accessible depuis un ou plusieurs
autres modules. On appelle lien l'objet relais, qui permet à un
module d'accéder à un objet appartenant à un autre module.
L'établissement de ce lien passe par un intermédiaire, le
nom du lien, permettant de le désigner dans les deux modules. Ce
nom est en général une chaîne de caractères. Nous
appellerons lien à satisfaire la partie du lien située chez
l'accédant, et lien utilisable la partie située chez
l'accédé (figure 5.1).
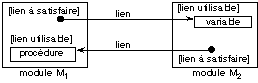
Fig. 5.1. La notion de lien.
5.2.1. Expression de la nature du lien dans le module source
Lors de la traduction d'un module, le traducteur doit
être capable de définir ces deux types de liens. Par ailleurs, le
traitement, par le traducteur, des objets qu'ils désignent est
différent, puisque un lien à satisfaire correspond à un
objet pour lequel le traducteur ne réserve pas de place en
mémoire. Certains de ces objets sont connus, a priori, du traducteur. Il
s'agit, en particulier, de tous les sous-programmes de travail liés au
langage, dont le traducteur décide d'engendrer l'appel au lieu de la
séquence d'instructions correspondante: conversion de type,
contrôle et transmission de paramètres des procédures du
langage source, fonctions standards, etc... Pour ces objets, c'est le traducteur
qui décide des liens à satisfaire.
Quant aux objets de l'utilisateur, le traducteur doit
déterminer à quelle catégorie ils appartiennent:
- Les objets peuvent être internes au
module, et inaccessibles de l'extérieur du module. Aucun lien n'est
à engendrer dans le module objet.
- Les
objets peuvent être internes au module, et accessibles de
l'extérieur du module. On dit qu'ils sont exportés, ou
encore publics. Le traducteur doit engendrer un lien utilisable, dont le
nom est alors l'identificateur désignant l'objet dans le
module.
- Les objets peuvent ne pas appartenir au
module, mais être accédés depuis ce module. On dit qu'ils
sont importés, ou encore externes. Le traducteur doit
engendrer un lien à satisfaire, dont le nom est alors l'identificateur
désignant l'objet dans le module.
Le langage de
programmation doit préciser la façon dont le programmeur exprime
cette catégorie au traducteur. S'il ne le fait pas, c'est alors au
concepteur du traducteur de le préciser, mais ceci entraîne une
divergence entre les traducteurs différents du même langage, et
nuit à la portabilité des programmes.
La catégorie d'un objet peut être implicite, ou
partiellement implicite, comme dans le cas du FORTRAN, qui considèrera,
par exemple, comme sous-programme externe un objet désigné par un
identificateur non déclaré, et dont une occurence dans le module
source est suivie du symbole "(".
La catégorie peut être définie
explicitement, c'est-à-dire que les objets sont considérés
normalement comme uniquement internes, sauf si le programmeur les
spécifient explicitement comme exportés ou importés. Ceci
peut présenter diverses formes, comme le montrent les exemples suivants,
où A est importé et
B est exporté.
Pascal 6.02 Multics
program P (A); (* importation de A *)
var def B: integer; (* exportation de B *)
procedure A (x : integer); pascal; (* déclaration du type de A *)
begin ...end.
Pascal Multics, versions ultérieures
program P;
$IMPORT 'A(pascal)': A$ (* importation de A *)
$EXPORT B$ (* exportation de B *)
var B: integer; (* déclaration de B *)
procedure A(x: integer); external; (* déclaration du type de A *)
begin ...end.
Pascal Microméga
program P;
var B: integer; (* exportation implicite *)
procedure A(x: integer); external;(*déclaration et importation *)
begin ...end.
Certains
langages récents orientés vers la modularité
séparent le module source en deux parties, la partie définissant
les exportations, et celle définissant l'implantation du module. Ainsi,
en langage Ada, la partie spécification contient une liste de
déclaration de types, d'objets ou de procédures qui appartiennent
au module, et sont exportés par ce module, alors que la partie
corps renferme l'implantation du module, et ce qui lui est propre.
L'importation se fait en nommant dans une clause particulière
située devant le module, la liste des modules dont on désire
importer des objets. L'exemple ci-dessus se décrirait de la façon
suivante:
package E is
procedure A (x : integer); -- procédure du module exportée
end E;
package P is
B : integer; -- exportation de B
end P;
with E; -- importation des objets du module E
package body P is
-- contenu de P
end P;
5.2.2. Représentation des liens dans le module objet
La représentation d'un lien utilisable dans un module
objet ne pose guère de problèmes. Il s'agit d'un couple
<nom, valeur>, où la valeur
définit d'une part la section contenant l'objet, d'autre part l'adresse
relative de l'objet dans la section. Lorsqu'on connait l'adresse effective
d'implantation de cette section, il est ainsi possible de calculer la valeur
finale du lien. En reprenant l'exemple du module assembleur, et en supposant que
AJOUT10 et
AJOUT16 sont déclarés
publics, l'assembleur fournira les informations suivantes:
AJOUT10 00 relative au code
AJOUT16 0A relative au code
Ceci
permettra à l'éditeur de liens de calculer les adresses finales
suivantes:
AJOUT10 012340
AJOUT16 01234A
La
représentation d'un lien à satisfaire dans un module objet peut
présenter diverses formes suivant les systèmes, dont voici
quelques exemples:
1) C'est un couple <nom,
liste> qui associe au nom du lien la liste des emplacements du
module qui font référence au lien (nous notons
contenu[j] le contenu de l'emplacement
d'adresse j du module).
- Cette liste peut être obtenue par
chaînage de ces emplacements entre eux,
liste étant alors l'adresse du
premier emplacement, et chacun d'eux contenant l'adresse du suivant.
L'établissement des liaisons est alors obtenu par l'algorithme
suivant:
procédure relier (liste, valeur);
début
tant que liste <> nil faire
x := contenu [liste]; { x repère le suivant de la liste }
contenu [liste] := valeur; { on établit le lien }
liste := x;
fait;
fin;
- Cette liste peut être un tableau des
adresses des emplacements. L'établissement des liaisons est alors obtenu
par l'algorithme suivant:
procédure relier (liste, n, valeur);
début
pour i de 1 à n faire
contenu [liste [i]] := contenu [liste [i]] + valeur;
fait;
fin;
Contrairement
à la deuxième représentation, la première ne permet
pas de modifier statiquement le lien, comme, par exemple, dans
A + 5.
2) C'est un couple
<nom,
numéro>, qui définit le
numéro sous lequel est référencé dans le module ce
lien à satisfaire. Les références au lien sont alors
transcrites dans le module objet sous forme d'informations de translation:
“ajouter à l'emplacement e, la valeur du
lien n”.
5.3. Fonctionnement de l'éditeur de liens
L'édition de liens peut se faire parfois de
façon dynamique (Multics). Dans ce cas, le module correspondant au
programme principal est lancé par l'utilisateur, sous sa forme objet
éditable. Lorsque ce module accède à un lien à
satisfaire, le système (matériel et logiciel) appelle alors
automatiquement l'éditeur de liens pour trouver le module contenant ce
lien en tant que lien utilisable, et établir la liaison. Peu de
systèmes offrent cependant cette possibilité. Dans tous les autres
cas, l'édition de liens est faite de façon statique par appel de
l'éditeur de liens (ou relieur, ou linker), en fournissant
en paramètres la liste des modules à relier, L =
(M1, M2, ... , Mn
).
5.3.1. Édition simple de la liste L
L'édition de liens d'un ensemble fixe de modules
donnés par une liste L peut se faire en trois étapes. Les
deux premières étapes sont parfois fusionnées.
Étape 1: Construction de la table des
adresses d'implantation des sections des différents modules, par
acquisition de leur taille depuis les modules objets, et placement de ces
sections les unes derrière les autres. En général ce
placement tient compte de la nature des sections, c'est-à-dire regroupe
ensemble les sections de même nature, ce qui permettra, à
l'exécution, de protéger différemment ces sections, et donc
d'en limiter les accès. Par exemple:
|
nature
|
opérations autorisées
|
|
code instruction
|
exécution
|
|
données constantes
|
lecture
|
|
données variables
|
lecture, écriture
|
Étape 2: Construction de la table des
liens utilisables. Cette table associe aux noms des liens l'adresse effective en
mémoire de l'objet que le lien désigne. Cette adresse est obtenue
par transformation de l'adresse relative dans sa section, fournie par le module
objet.
Étape 3: Construction du programme
final lui-même. Chaque module est translaté, en tenant compte des
informations de translation du module objet. Les noms des liens à
satisfaire sont recherchés dans la table des liens utilisables. S'ils y
sont trouvés, les emplacements du module, qui se réfèrent
à ce lien à satisfaire, sont modifiés conformément
à la valeur associée au lien dans la table. Si un lien à
satisfaire n'est pas trouvé dans la table, il reste indéfini dans
le programme (ou non résolu, ou unresolved), et un message
d'anomalie est alors imprimé par l'éditeur de liens. Ceci ne veut
pas dire que le programme ne peut s'exécuter, car une exécution
particulière peut ne pas accéder à ce lien, par exemple, en
phase de mise au point partielle. Évidemment un programme
“opérationnel” ne devrait plus contenir de liens
indéfinis.
5.3.2. Construction de la table des liens
Posons LUM l'ensemble des noms des liens
utilisables d'un module M, et LASM l'ensemble des noms
des liens à satisfaire du module M.
Remarquons d'abord que les ensembles LUM
devraient être deux à deux disjoints pour les modules d'une
même liste, dont on veut faire l'édition de liens. Si ce n'est pas
le cas, un même lien possède plusieurs définitions, parmi
lesquelles l'éditeur de liens fera, en général, un choix,
qui ne sera pas forcément le bon; il signalera cette anomalie. Les
définitions multiples peuvent se décrire par l'ensemble
suivant:
Par ailleurs, nous avons vu que certains liens à
satisfaire pouvaient ne pas être trouvés. Nous pouvons
définir, pour une liste de modules L :
La deuxième étape de l'édition de liens
peut être modifiée pour permettre la connaissance de
LASL dès la fin de cette étape, et avant
d'entamer la troisième étape. Il suffit, pour cela, de remplacer
la table des liens utilisables par une table plus générale, dite
table des liens (figure 5.2), qui associe à chaque nom de
lien:
- l'état du lien considéré
comme utilisable, à satisfaire ou non
résolu,
- la valeur du lien, qui n'a de
signification que lorsque le lien est dans l'état
utilisable.
|
nom
|
état
|
valeur
|
|
A
|
à_satisfaire
|
|
|
B
|
utilisable
|
3281
|
Fig. 5.2. Exemple du contenu de la table
des liens après traitement du module donné en
§5.2.1.
La construction de la table des liens peut alors être
obtenue en parcourant les modules de la liste, et en effectuant pour chacun
d'eux l'algorithme de la figure 5.3. Cet algorithme lui-même met dans la
table des liens les noms de tous les liens rencontrés dans ces modules,
en tenant compte de leur état. En particulier, tous les noms qui
correspondent à un lien utilisable dans un module de la liste, sont dans
la table avec l'état utilisable, à la fin de
l'étape. De même, tous les noms qui correspondent à un lien
à satisfaire dans un des modules de la liste, sont dans la table avec
l'état à_satisfaire si aucun des modules de la liste ne
contient de lien utilisable de même nom. Après avoir
exécuté l'algorithme de la figure 5.3 sur tous les modules de la
liste, on a:
LASL = { n | n
⊂ table ∧
état (n) = à_satisfaire }
procédure lire_les_liens_du_module;
début pour tous les liens du module faire
soit n son nom, recherche de n dans la table
si n a été trouvé alors
si n ⊂ LUM alors
si état (n) = utilisable alors double_définition (n)
sinon état (n) := utilisable; valeur (n) := sa_valeur;
finsi;
finsi { s'il est lien à satisfaire dans le module,
et déja dans la table, on ne fait rien }
sinon
ajouter n dans la table;
si n ⊂ LUM alors état(n) := utilisable; valeur(n) := sa_valeur;
sinon état (n) := à_satisfaire;
finsi;
finsi;
fait;
fin;Fig.
5.3. Procédure de lecture des liens d'un module et de
construction de la table des liens.
5.3.3. Notion de bibliothèque
La notion de bibliothèque de modules objets a pour but
de compléter la liste L avec des modules provenant de la
bibliothèque, et qui, par les liens utilisables qu'ils contiennent,
permettraient de satisfaire les liens de LASL. On peut
distinguer trois fonctions qui justifient le regroupement de modules objets dans
une bibliothèque:
- La bibliothèque de calcul contient
des sous-programmes standards tout faits, tels que
sinus,
cosinus,
racine_carrée, etc... On peut y
adjoindre également les sous-programmes de travail liés à
un langage, dont nous avons déjà parlé, et dont le
traducteur génère l'appel au lieu de la séquence
d'instruction correspondante.
- La
bibliothèque d'interface système contient les
sous-programmes qui exécutent les appels systèmes. Si un tel appel
peut paraître équivalent à un appel de sous-programme, nous
avons vu dans le chapitre 2 deux raisons militent pour les traiter
différemment. La première est le besoin éventuel de faire
passer le processeur en mode maître et lui permettre de disposer du jeu
complet d'instructions. La deuxième est qu'un contrôle doit
être effectué au moment de l'appel, et il ne faut pas qu'un
programmeur mal intentionné puisse contourner ce contrôle, or la
connaissance de l'adresse A de la fonction dans le système permettrait au
programmeur de faire un appel au sous programme en A+5 par exemple. Notons que,
par ailleurs, si les programmes exécutables sont reliés
directement par l'éditeur de liens avec les sous-programmes du
système, un changement de système nécessiterait de refaire
l'édition de liens de tous les programmes exécutables de
l'installation. Aussi, comme nous l'avons déjà dit, un appel
système est en général réalisé par une
instruction particulière de la machine (par exemple, SVC pour
supervisor call sur IBM370, ou INT pour interrupt sur
MS-DOS). Ces instructions déroutent le processeur vers un emplacement de
mémoire connu du matériel, où se fera le contrôle et
la redirection vers les instructions du système qui réalisent la
fonction demandée. Par ailleurs, le passage des paramètres se fait
souvent en utilisant les registres du processeur et non en utilisant une pile
comme le font beaucoup d'implantations des langages de programmation. Les
sous-programmes de la bibliothèque d'interface système ont pour
but de préparer les paramètres et d'exécuter l'instruction
d'appel, en évitant ainsi aux traducteurs d'être trop
dépendants du système.
- La
bibliothèque de l'utilisateur contient les sous-programmes
écrits par un utilisateur ou un groupe d'utilisateurs pour les besoins
courants de leurs applications. Évidemment il peut en exister plusieurs
qui satisfont des besoins spécifiques.
Une telle
bibliothèque est, en général, une structure de
données constituée, au minimum de la collection des modules objets
qu'elle contient, et éventuellement d'une table dont les entrées
sont les noms des liens utilisables de ces modules, et qui associe à
chacune de ces entrées le module qui le contient comme lien utilisable.
Cette table permet d'éviter de devoir parcourir l'ensemble des modules de
la bibliothèque pour savoir celui qui contient un lien utilisable de nom
donné (figure 5.4).
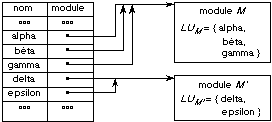
Fig. 5.4. Exemple de structure de
bibliothèque de modules objets.
En général, les ensembles des liens utilisables
des modules situés dans une même bibliothèque B sont deux
à deux disjoints, c'est-à-dire que:
∀ M, M'
⊂ B, LUM
∩ LUM ' =
Ø
ce qui garantit l'unicité du module associé
à une entrée de la table.
Par contre, une édition de liens particulière
peut demander l'utilisation de plusieurs bibliothèques, dont les
ensembles de liens utilisables ne sont pas forcément disjoints. Les
bibliothèques doivent alors être fournies dans l'ordre où
l'on désire que l'éditeur fasse la recherche. Ainsi en UNIX, la
demande d'édition de liens suivante:
ld A.o B.o C.o -lpc -lm -lc
est
interprétée comme l'édition de liens, tout d'abord, de la
liste des trois modules A.o,
B.o et
C.o, et qui peut être
complétée par des modules recherchés dans les
bibliothèques pc,
m ou
c, dans cet ordre.
5.3.4. Adjonction de modules de bibliothèques
Plus généralement, considérons
l'édition de liens d'une liste L avec les bibliothèques B1, B2,
..., Bp. L'éditeur de liens commence par construire la table des liens
à partir de la liste L. Il doit ensuite chercher à étendre
cette liste initiale pour y ajouter des modules provenant des
bibliothèques, et qui permettent de satisfaire des liens qui ne le sont
pas encore. Chaque fois qu'il trouve un tel module, il l'ajoute à la
liste L, et exécute l'algorithme de lecture de ses liens
présenté plus haut. Pour éviter de rechercher
indéfiniment un lien à satisfaire qui n'existe, comme lien
utilisable, dans aucun module de bibliothèques, on se sert de
l'état inexistant. Nous utiliserons les notations suivantes:
- LAS = { n | n
⊂ table ∧
état (n) = à_satisfaire
}
- LU = { n | n
⊂ table ∧
état (n) = utilisable }
- LIN
= { n | n ⊂ table
∧ état (n) = inexistant
}
Deux méthodes peuvent être utilisées
par l'éditeur de liens. Ces deux méthodes peuvent ne pas donner le
même résultat.
i) Chaque lien est recherché successivement dans
les bibliothèques. On obtient l'algorithme de la figure 5.5. On notera
qu'à la fin du traitement, on a:
tant que LAS ≠ Ø faire
soit n ⊂ LAS
i := 1;
tant que état (n) = à_satisfaire faire
si n est une entrée dans la table de Bi alors
soit M le module qui lui est associé
ajouter M à L
lire_les_liens_du_module (M)
sinon si i < p alors i := i + 1
sinon état (n) := inexistant
finsi
finsi
fait
fait
Fig.
5.5. Première méthode de recherche en
bibliothèque.
En d'autres termes, si un lien est inexistant à la fin
du traitement, c'est qu'il n'existe effectivement comme lien utilisable dans
aucun module de l'une des bibliothèques.
ii) La recherche est effectuée pour tous les liens en
parcourant les bibliothèques successives. C'est la méthode
utilisée habituellement dans l'éditeur de liens de UNIX.
L'algorithme est donné en figure 5.6. On notera que dans ce cas, il est
possible qu'à la fin du traitement on ait:
Il suffit qu'un tel lien à satisfaire soit introduit
par un module M provenant d'une bibliothèque Bi
, et qu'il soit lien utilisable dans M' appartenant à
Bj , avec j<i, sans l'être dans aucun M"
appartenant à Bk , avec
i≤k.
pour i de 1 à p faire
tant que LAS ≠ Ø faire
soit n ⊂ LAS
si n est une entrée dans la table de Bi alors
soit M le module qui lui est associé
ajouter M à L
lire_les_liens_du_module (M)
sinon état (n) := inexistant
finsi
fait
tant que LIN ≠ Ø faire { préparer pour la bibliothèque suivante }
soit n ⊂ LIN
état (n) := à_satisfaire
fait
faitFig.
5.6. Deuxième méthode de recherche en
bibliothèque.
L'intérêt de cette deuxième méthode
est de permettre de prendre en compte des bibliothèques non
structurées, qui sont simplement une suite de modules (sans table), par
simple parcours de cette suite. Il est évident que l'ordre dans lequel
les modules sont placés dans cette suite est important. Si un module
M d'une bibliothèque contient un lien à satisfaire qui est
lien utilisable d'un module M' de la même bibliothèque, il
faut que le module M précède le module M' pour que
la sélection de M entraîne celle de M'.
Il va sans dire que, lorsque l'algorithme d'adjonction de
modules de bibliothèques est terminé, l'éditeur de liens
exécute l'étape 3 de construction du programme exécutable
final, en utilisant la liste L ainsi augmentée par la recherche
des modules provenant de bibliothèques.
5.3.5. Edition de liens dynamique
Certains systèmes offrent la possibilité de
retarder l'édition de liens, soit jusqu'au moment du chargement du
programme, soit jusqu'au moment où la liaison est utilisée au
moment de l'exécution. Ceci peut se faire soit module par module (c'est
la méthode par défaut utilisée dans Multics en 1970), soit
au niveau global d'une bibliothèque complète (c'est la
méthode utilisée par windows 95). Une des méthodes
utilisées consiste à remplacer les modules ainsi reliés par
un module particulier, que nous appelons module relais, qui va servir
d'intermédiaire aux liaisons. Ce module est en fait une table où
chaque entrée est un relais vers un lien utilisable de l'un des modules
effectifs et tient lieu de lien utilisable pour l'édition de lien
statique. Lors du chargement effectif des modules correspondants, les
entrées de cette table assureront le relais vers le lien effectif du
module. La figure 5.7 montre la liaison entre un lien à satisfaire du
module M1 vers un lien utilisable du module M2, par l'intermédiaire du
module relais. L'éditeur de lien ne se préoccupe que du lien entre
le module M1 et le module relais, l'établissement du lien dynamique
étant reporté à un instant ultérieur (chargement ou
exécution).

Fig. 5.7. Liaison dynamique.
5.4. Notion de recouvrement
Lorsqu'on construit un programme de grande taille, il est
possible que la mémoire centrale réelle dont on dispose soit
insuffisante. Certains systèmes résolvent ce problème en
offrant une mémoire virtuelle de grande taille (par exemple 2 Go), et se
chargent de ne mettre en mémoire réelle, à un instant
donné, qu'une partie du programme et des données, celle qui est
nécessaire à son exécution à cet instant. D'autres
systèmes n'offrent pas cette possibilité qui nécessite des
dispositifs matériels. Dans ce cas, l'éditeur de liens propose
souvent une solution par le biais de ce que l'on appelle le recouvrement
(en Anglais overlay).
La mémoire virtuelle entraîne, sans doute, la
disparition de cette notion dans un avenir proche. Le principe de base reste
cependant, même si l'utilisateur ne s'en aperçoit pas: à un
instant donné, un programme n'utilise qu'une petite partie du code et des
données qui le constituent. Les parties qui ne sont pas utiles en
même temps peuvent donc se “recouvrir”, c'est-à-dire
occuper le même emplacement en mémoire réelle. Dans le cas
de la mémoire virtuelle, ce recouvrement sera assuré dynamiquement
par le système, au fur et à mesure de l'exécution du
programme. S'il n'y a pas de mémoire virtuelle, l'utilisateur doit
assurer lui-même un découpage de son programme, indiquer ce
découpage à l'éditeur de liens et préciser les
parties qui peuvent se recouvrir, et prévoir explicitement dans son
programme des opérations de chargement de ces parties lorsqu'elles sont
nécessaires. L'éditeur de liens tiendra compte de ces informations
lors de la définition des adresses d'implantations des différents
modules du programme. En général, le découpage et le
recouvrement sont indiqués sous la forme d'un arbre, dont la figure 5.8
est un exemple. L'éditeur de liens déduira de cet arbre que, entre
autre, les modules E et
H peuvent être implantés au
même endroit, de même que les modules
C, J
et Q.
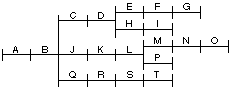
Fig. 5.8. Exemple d'arbre de
recouvrement.
5.5. Les références croisées
L'éditeur de liens, au cours de son travail, dispose de
certaines informations qui peuvent être intéressantes pour le
programmeur (en dehors des anomalies rencontrées).
- La carte d'implantation des modules peut aider
l'utilisateur dans la mise au point ou la maintenance du programme, lorsqu'une
erreur est détectée à l'exécution à une
adresse donnée. Nous verrons, cependant, que les metteurs au point
peuvent apporter une aide plus intéressante de ce point de vue. Notons,
pour le moment, qu'ils exploiteront cette carte d'implantation si
l'éditeur de liens la leur fournit dans le programme
exécutable.
- Au cours du travail,
l'éditeur de liens associe les liens à satisfaire d'un module aux
liens utilisables des autres modules. Il peut être intéressant
qu'il fournisse cette information à l'utilisateur. Il s'agit alors
d'indiquer à cet utilisateur, pour chaque lien utilisable, la liste des
modules (et éventuellement les emplacements à l'intérieur
de ces modules) qui ont ce lien comme lien à satisfaire. En d'autres
termes, on peut ainsi savoir “qui utilise quoi”. C'est ce que l'on
appelle les références
croisées.
Ces références
croisées peuvent être obtenues en sous-produit de l'édition
de liens. Il est aussi possible de réaliser un programme
spécifique pour cela, dont le fonctionnement sera assez voisin de
l'éditeur de liens, du point de vue de la gestion de la table des liens.
Évidemment, un tel outil est alors plus simple, puisqu'il n'a pas
à construire le programme exécutable. Il offre aussi l'avantage de
pouvoir être appliqué sur un ensemble de modules qui ne constituent
pas un programme complet, sans avoir de messages d'erreurs inutiles. Voici un
exemple d'édition de telles références
croisées:
|
lien
|
module où il est "utilisable"
|
modules et emplacements où il est "à
satisfaire"
|
|
alpha
|
M1
|
M2(10, 50, 86), M3(26)
|
|
bêta
|
M2
|
M1(104), M4(34)
|
|
gamma
|
M3
|
M4(246, 642)
|
|
delta
|
M3
|
M5(68, 94), M6(4), M7(456,
682, 624)
|
L'intérêt de disposer de ces réferences
croisées est multiple, suivant que l'on regarde les variables ou les
sous-programmes, et que l'on se place du point de vue de la mise au point ou de
la maintenance des applications.
- Par exemple, si un identificateur exporté
par un module désigne une variable, on peut ainsi savoir la liste des
modules qui accèdent directement à cette variable. Outre l'aspect
contrôle ainsi obtenu, cela permet, en phase de mise au point, si la
valeur n'est pas conforme à ce qu'elle devrait être, de savoir
quels sont les modules qui peuvent être en cause. Cela permet
également, en phase de maintenance, si on change l'interprétation
du contenu de cette variable, de savoir quels sont les modules qui sont
concernés par ce changement.
- De
même, si un identificateur exporté par un module désigne un
sous-programme, on peut connaître la liste des modules où se
trouvent les appels de ce sous-programme. En phase de mise au point d'une
application, lorsque l'on constate que les variables permanentes internes au
module ne sont pas conformes, il faut déterminer quels sont les appels
précédents qui ont conduit à cette non-conformité.
On peut alors savoir quels sont les modules qui peuvent être en cause. En
phase de maintenance, en cas de changement de la spécification ou du
fonctionnement de ce sous-programme, on peut savoir quels sont les modules qui
sont concernés par ce changement.
Enfin, la
connaissance des relations entre les modules que l'on peut ainsi obtenir, peut
permettre d'améliorer le découpage de ces modules en regroupant
ensemble les parties de module ou les modules entiers qui ont de fortes
interactions. Ces relations peuvent être également utiles pour
faciliter la construction des bibliothèques de modules lorsque l'ordre
des modules a de l'importance pour l'éditeur de liens.
5.6. Le chargement
Plusieurs raisons militent pour que le résultat de
l'édition de lien ne soit pas le programme installé quelque part
en mémoire centrale prêt à être exécuté.
La première est que cela limiterait arbitrairement la taille des
programmes, puisqu'elle ne pourrait atteindre que l'espace total moins l'espace
occupé par l'éditeur de liens lui-même. La deuxième
raison est que l'édition de liens consomme du temps machine, et qu'il
n'est pas économique de la refaire chaque fois que l'on désire
faire exécuter le programme lui-même. Il s'ensuit que
l'éditeur de liens produit plutôt un fichier contenant le programme
exécutable.
Pour exécuter un programme, il faut donc prendre sa
version exécutable, et la mettre en mémoire (réelle ou
virtuelle). On appelle chargement cette opération, et
chargeur le programme qui l'effectue. Cette opération pourrait
consister en une simple lecture du contenu du fichier dans un emplacement
mémoire fixé a priori par l'éditeur de liens. Cette
méthode est simple, mais restrictive, puisqu'il faut décider de
l'endroit définitif en mémoire où le programme
s'exécutera au moment où l'édition de liens est faite. Elle
n'est souvent utilisée que pour les programmes autonomes (stand
alone), car elle permet d'avoir des programmes d'amorçage très
simples.
Il est facile de concevoir que, puisque l'éditeur de
liens a disposé des informations qui lui ont permis de translater les
modules, il laisse ces informations dans le fichier qui contient le programme
exécutable. Le chargeur peut alors les utiliser pour translater le
programme complet, et le mettre ainsi n'importe où en mémoire. Il
est évident que les informations de translations provenant des modules
doivent être modifiées légèrement pour être
maintenant relatives au programme. En général, l'éditeur de
liens fournira également la taille mémoire centrale totale
nécessaire à l'exécution du programme, qu'il déduira
des tailles de l'ensemble des modules qui le composent.
Enfin, une dernière information minimale est
nécessaire au chargeur pour terminer le travail, et lancer
l'exécution du programme, c'est l'adresse de lancement, ou
l'adresse de l'emplacement où se trouve la première instruction
à exécuter. Pour l'utilisateur, c'est la première
instruction d'un module particulier, qu'est son programme principal. Pour
les langages évolués, le compilateur est à même de
déterminer si un module est ou non un programme principal, et si oui
quelle est l'adresse dans le module objet de la première instruction
à exécuter. Pour le langage d'assemblage, cette information est,
en général, précisée explicitement par le
programmeur à l'assembleur. Les traducteurs doivent donc informer
l'éditeur de liens de l'adresse de lancement éventuelle du module.
Comme l'éditeur de liens est en présence de plusieurs modules, il
ne devrait trouver qu'un et un seul module contenant une telle adresse de
lancement, qu'il peut alors transmettre au chargeur, après
éventuelle modification pour la rendre relative au programme et non plus
au module dont elle provient.
Par ailleurs, le programme exécutable a
été conçu pour être exécuté dans un
certain environnement. S'il est prévu pour fonctionner en autonome, son
environnement est alors simplement la machine nue. S'il est prévu pour
fonctionner sur un système particulier, il peut être
nécessaire d'établir les liaisons avec ce système. Nous
avons déjà mentionné l'existence de bibliothèque
d'interface système qui peut résoudre complètement ces
liaisons. Nous avons également mentionné (§5.3.5) que
certains systèmes prévoient de retarder les liaisons effectives
avec certains sous-programmes standards, ce qui permet en particulier de les
partager entre l'ensemble des programmes présents en mémoire, de
façon à économiser de la place (VMS ou Windows NT par
exemple). Le chargeur doit alors remplir la table contenue dans le module relais
avec les adresses effectives actuelles de ces sous-programmes. On peut
considérer que le programme en mémoire est prévu pour
s'exécuter sur une machine abstraite, et que le chargeur doit non
seulement mettre le programme en mémoire, mais aussi préparer la
machine abstraite nécessaire à son exécution.
5.7. Conclusion
+ La translation d'un
module consiste à modifier son contenu pour qu'il puisse
s'exécuter à un endroit différent de celui pour lequel il
était prévu initialement.
+ Un lien est
l'information qui permet à un module d'accéder à un objet
appartenant à un autre module. Il est désigné par un nom.
On appelle lien à satisfaire la partie du lien située chez
l'accédant, et lien utilisable celle située chez
l'accédé.
+ L'expression de la
nature d'un lien dépend du langage de programmation et du traducteur.
Elle peut prendre des formes variées.
+ L'édition de
liens se fait en deux phases. La première construit la table de
l'ensembles des liens trouvés dans les modules à relier. La
seconde construit le programme exécutable en translatant les modules et
en remplaçant les liens à satisfaire par la valeur du lien
utilisable correspondant.
+ Entre les deux
phases, l'éditeur de liens peut compléter la liste des modules
à relier avec des modules provenant de bibliothèques, en tenant
compte des liens restant à satisfaire.
+ Une
bibliothèque peut être une simple collection de modules parcourue
séquentiellement par l'éditeur de liens, mais l'ordre des modules
est important. Elle peut être structurée de façon à
savoir rapidement quel module, s'il existe, contient un lien donné comme
lien utilisable.
+ Une
bibliothèque regroupe en général des modules de
fonctionnalité voisine. On peut avoir, par exemple, une
bibliothèque de calcul, une bibliothèque d'interface
système, et des bibliothèques spécifiques aux
utilisateurs.
+ Le recouvrement est
une technique qui permet de diminuer l'encombrement total en mémoire
centrale d'un programme, en décidant que des parties du programme peuvent
se trouver au même endroit, car elles ne sont pas utiles au même
moment pour la bonne exécution du programme.
+ L'édition des
références croisées consiste à éditer une
table qui, pour chaque lien trouvé dans une liste de module, donne le
module dans lequel il est utilisable, et ceux dans lesquels il est à
satisfaire. Elle peut être obtenue en sous-produit de l'édition de
liens, ou par un outil spécifique. Elle est utile pour la mise au point
et pour la maintenance.
+ Le chargement est
l'opération qui consiste à mettre en mémoire centrale un
programme exécutable, avec une éventuelle translation, et à
en lancer l'exécution. Il consiste également à construire
la machine abstraite demandée par le programme.