4
La traduction des langages de programmation
Le langage de la machine est en fait constitué de bits,
ce qui le rend impraticable par l'homme. La première étape a
été de concevoir des langages simples, assez proches du langage de
la machine pour pouvoir être traduits facilement. Il s'agissait alors de
remplacer les codes binaires des opérations de base par des codes
mnémoniques plus faciles à se rappeler, la traduction consistant
à retrouver les codes binaires correspondants. Ceci a conduit aux
langages d'assemblage qui se sont perfectionnés, tout en restant
proches de la machine, dont le programmeur devait avoir une connaissance
approfondie.
La difficulté de mise en œuvre de ce type de
langage, et leur forte dépendance avec la machine a
nécessité la conception de langages évolués,
plus adaptés à l'homme, et aux applications qu'il cherchait
à développer. Faisant abstraction de toute architecture de
machine, ces langages permettent l'expression d'algorithmes sous une forme plus
facile à apprendre, et à dominer. On s'intéresse alors aux
vrais besoins d'expression du programmeur plutôt qu'aux mécanismes
fournis par la machine. Il s'ensuit une spécialisation du langage suivant
la nature des problèmes à résoudre et non suivant la
machine qui sera utilisée pour les résoudre. Ainsi, FORTRAN est un
langage destiné aux applications scientifiques, alors que COBOL est
destiné aux applications de gestion.
Pour l'ordinateur, un programme écrit dans un langage
qui n'est pas le sien est en fait une simple suite de caractères plus ou
moins longue. Si le langage est un langage d'assemblage, un programme
spécialisé, l'assembleur, parcourt cette suite de
caractères pour reconnaître les différents
mnémoniques, et les remplacer par leur équivalent binaire dans le
langage de la machine (c'est une approche très sommaire!). Si le langage
est un langage évolué, le programme spécialisé,
chargé de la traduction, peut se présenter sous l'une des deux
formes suivantes:
- L'interpréteur parcourt en
permanence la suite de caractères, analyse les actions définies
par le programme, exprimées dans le langage évolué, et
exécute immédiatement la séquence d'action de la machine
qui produit les mêmes effets.
- Le
compilateur parcourt la suite de caractères, analyse les actions
du programme et la traduit en une suite d'instructions dans le langage de la
machine.
Il s'ensuit évidemment que l'analyse des
actions est une phase plus complexe et plus difficile que pour l'assembleur.
Notons que l'interpréteur simule une machine qui comprend le langage
évolué, alors que le compilateur fait une traduction dans le
langage de la machine, et c'est cette traduction qui est exécutée.
Il s'ensuit qu'un interpréteur est plus facile à utiliser pour le
programmeur, mais le résultat est moins efficace que l'exécution
du programme compilé, car les actions du programme sont analysées
chaque fois qu'elles doivent être exécutées. Par exemple,
une action située à l'intérieur d'une boucle
exécutée 10000 fois, sera analysée 10000 fois.
Notons qu'il est possible de combiner les deux. Plusieurs
environnements de programmation ont été ainsi construits autour du
Pascal vers 1971, de Caml vers 1988 et de Java en 1998, chacun d'eux ayant un
fonctionnement analogue. Nous décrivons celui de Java qui est le plus
récent. On définit d'abord une machine virtuelle universelle,
ayant son propre langage, appelé bytecode. En général ces
machines n'existent pas physiquement, bien qu'il y ait eu des tentatives dans ce
sens. On compense cette absence en la simulant par logiciel, c'est-à-dire
en créant un interpréteur de bytecode. La compilation consiste
alors à traduire un programme Java en bytecode qui peut donc être
exécuté à l'aide de cet interpréteur. Nous
reviendrons sur ce principe à la fin du chapitre.
Quels que soient le langage et la méthode de traduction
utilisés, le programme est toujours une suite de caractères. C'est
ce que nous appellerons un programme source. Le traducteur doit analyser
cette suite de caractères pour retrouver les constituants essentiels,
vérifier la conformité avec la définition du langage, et en
déduire la sémantique. Un interpréteur doit ensuite
exécuter les actions correspondant à cette sémantique,
alors qu'un assembleur ou un compilateur doit traduire cette sémantique
dans un autre langage. On appelle programme objet, le résultat de
cette traduction. Par ailleurs, nous avons vu qu'il pouvait être
intéressant de découper un programme en morceaux, traduits
séparément, et rassemblés ultérieurement par
l'éditeur de liens (évidemment, ceci n'est pas possible avec un
interpréteur). On parle alors respectivement de module source et
de module objet. Le langage utilisé doit permettre la prise en
compte de ce découpage en module.
4.1. L'analyse lexicale
La suite de caractères représentant le module
est la forme concrète de communication entre le programmeur et le
traducteur. Mais chaque caractère pris individuellement n'a pas, en
général, de signification dans le langage lui-même. Par
exemple, dans un langage tel que Pascal, chaque caractère de la suite
“begin” n'a pas de
signification, alors que la suite elle-même est un symbole du
langage. Il apparaît alors nécessaire de découper le module
source, en tant que chaîne de caractères, en une suite de symboles
du langage, chaque symbole étant représenté par une suite
de caractères.
Considérons, par exemple, le petit bout de programme
source suivant:
begin x := 23; end
Cette
suite de caractères doit être découpée de la
façon suivante:
mettant en avant les six symboles dont est constitué le
programme. Pour des raisons de commodité de traitement évidentes,
on donne à chacun des symboles, une forme de représentation
interne à la machine. Cette opération de transformation du module
source en une représentation interne codée s'appelle l'
analyse
lexicale. Cette opération n'est évidemment possible que si la
structure lexicale du langage est correctement
définie
[1]. Ceci implique quelques
contraintes habituelles sur la définition des langages:
- Un identificateur commence par une lettre, et ne
peut comporter que des lettres, des chiffres, ou éventuellement des
caractères spéciaux qui ne sont pas utilisés ailleurs ("_"
ou "$", par exemple). On peut décrire cela sous la forme suivante:
identificateur ::= lettre { lettre | chiffre | "_" }
- Une constante numérique commence par un
chiffre, même si elle est dans une base supérieure à 10. On
peut décrire cela sous la forme suivante:
constante ::= chiffre { chiffre | lettre }
- Les mots clés ont souvent la forme
lexicale des identificateurs, et ne sont pas alors utilisables en tant
qu'identificateur. C'est ce que l'on appelle encore les mots
réservés.
- Les opérateurs
peuvent être représentés soit par l'un des caractères
spéciaux habituels, tels que par exemple "+", "-", "=", etc..., mais
aussi par une combinaison de ces caractères spéciaux, comme par
exemple ":=", pourvu que cette combinaison ne soit pas
ambiguë.
- Les espaces, tabulations, fins de
lignes sont sans signification, c'est-à-dire qu'ils sont ignorés
au cours de l'analyse, si ce n'est qu'ils ne peuvent se trouver à
l'intérieur de la représentation d'un symbole. En d'autres termes,
ces caractères servent essentiellement à la présentation
externe, mais sont aussi des séparateurs entre deux symboles. Ainsi dans
le petit programme ci-dessus, l'espace permet à l'analyseur lexicale de
séparer le symbole begin de
l'identificateur x, et est donc
nécessaire à cet endroit, alors que les autres espaces sont
inutiles.
L'idée générale de
l'analyseur lexical est, sachant où commence un symbole dans la
chaîne de caractères du module source, de rechercher où il
se termine, en suivant les règles de définitions lexicales du
langage, puis de trouver où commence le symbole suivant, etc... Ces
techniques sont suffisamment générales et bien
maîtrisées pour permettre de construire des programmes capables de
produire automatiquement des analyseurs lexicaux à partir de la
définition lexicale d'un langage (par exemple, l'utilitaire lex
disponible sur Multics ou sur Unix).
4.2. L'analyse syntaxique
Le résultat obtenu après analyse lexicale est
une suite de symboles. Mais, toute suite de symboles ne constitue pas un
programme. Il faut donc vérifier la concordance de la suite avec la
structure du langage, sans se préoccuper, pour le moment, de la
sémantique du programme. C'est ce que l'on appelle l'analyse
syntaxique.
La plupart des langages de programmation modernes
définissent une syntaxe du langage, indépendante du contexte, par
des règles de production, qui décrivent la façon
dont on peut construire une suite de symboles pour qu'elle constitue un
programme. Le programmeur construit alors son programme en appliquant ces
règles de façon répétitive. L'analyse syntaxique
consiste à retrouver, à partir du programme source, ou en fait
à partir de la suite de symboles, quelles sont les règles que le
programmeur a appliquées. On utilise une syntaxe indépendante du
contexte, pour permettre cette reconstruction.
Une règle de production est, en général,
donnée sous une forme standard, dite forme normale de Backus-Naur.
Cette forme a l'avantage d'être simple et facile à assimiler. Par
exemple, la syntaxe d'une expression pourrait être donnée par
l'ensemble des règles suivantes:
<expression> ::= <facteur> | <facteur> <opérateur additif> <expression>
<facteur> ::= <terme> | <terme> <opérateur multiplicatif> <facteur>
<terme> ::= <identificateur> | <nombre> | ( <expression> )
<opérateur additif> ::= + | -
<opérateur multiplicatif> ::= * | /
La
première précise qu'une
expression est, soit un
facteur, soit un
facteur suivi d'un
opérateur additif suivi d'une autre
expression. De même la
dernière indique qu'un opérateur
multiplicatif est soit le symbole
*, soit le symbole
/. Plus généralement,
l'interprétation est la suivante:
- Les structures syntaxiques s'écrivent
sous la forme de mots encadrés par les signes
< et
>.
- Les
symboles s'écrivent sous leur forme
lexicale.
- Une règle de production comporte
une structure syntaxique unique à gauche du signe
::= et une ou plusieurs suites de symboles
et de structures syntaxiques, les suites étant séparées par
le signe | indiquant un choix parmi les
suites.
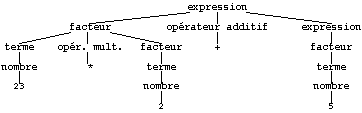
Dans le contexte des règles ci-dessus, la
suite de symboles "23 * 2 + 5" est une
expression constituée du
facteur "23 *
2", suivi de l'opérateur
additif "+" et de
l'expression
"5", qui est aussi un
facteur, puis un
terme et enfin un
nombre. Le
facteur "23 *
2" est lui-même constitué du
terme
"23" qui est un
nombre, suivi de
l'opérateur multiplicatif
"*" et du
facteur
"2", qui est un
terme, et un
nombre.
Cet exemple montre que, non seulement, l'analyse syntaxique
permet de contrôler que le programme est correctement écrit, mais
aussi, qu'elle permet de trouver la structure syntaxique de ce programme (figure
4.1). En particulier, si 2 + 5 est bien une
sous-suite de la suite donnée, elle ne correspond à aucune
structure syntaxique du langage dans cette
expression, alors que la sous-suite
23 * 2 a été reconnue comme
facteur de cette
expression.
Fig. 4.1. Structure syntaxique de
l'expression 23 * 2 + 5.
La rigueur de la définition des règles de
production tient à la nécessité d'éviter toute
ambiguïté dans la façon dont le programme est écrit.
Il est en effet nécessaire d'avoir une structure syntaxique unique pour
une suite donnée de symboles. Si plusieurs structures étaient
possibles, il pourrait arriver que le compilateur choisisse une structure qui ne
corresponde pas celle voulue par le programmeur, ce qui pourrait donner lieu
ensuite à une interprétation sémantique
différente.
4.3. L'analyse sémantique
Après avoir contrôlé la correction du
programme, et en avoir obtenu la structure syntaxique, la traduction continue
par la phase d'analyse sémantique, qui a pour but de trouver le
sens des différentes actions voulues par le programmeur. Trois
problèmes doivent alors être résolus:
- quels sont les objets manipulés par le
programme,
- quelles sont les
propriétés de ces objets,
- quelles
sont les actions du programme sur ces objets.
Les objets
manipulés sont en général désignés par le
programmeur au moyen d'identificateurs. Certains langages imposent que tous les
identificateurs soient explicitement “déclarés”,
c'est-à-dire, que le programmeur doit donner des indications au
traducteur sur la nature et les propriétés de l'objet
désigné par l'identificateur. D'autres langages déduisent
implicitement ces informations de la façon dont l'identificateur est
utilisé dans le programme. Les propriétés importantes sont
les suivantes:
- Le type de l'objet permet au traducteur
de connaître la sémantique des opérations effectuées
sur l'objet, et de déterminer ainsi la combinaison des opérations
de la machine qui auront le même effet.
- La
durée de vie de l'objet permet au traducteur de savoir s'il doit
prévoir ou non d'engendrer des instructions permettant sa création
ou sa destruction, et à quels moments de l'exécution du
programme.
- La taille de l'objet permet au
traducteur de savoir le nombre d'emplacements de mémoire occupés
par sa représentation.
- L'adresse de
l'objet permet au traducteur de désigner l'objet dans les intructions de
la machine qui le manipulent.
L'analyse sémantique
des actions du programme a pour but de permettre au traducteur de
déterminer avec précision la suite des actions qu'il doit
exécuter indépendamment de tout aspect langage. Prenons par
exemple le morceau de programme suivant:
var i: entier;
s: réel;
début
s := 0;
i := 0;
tantque i < 10 faire
s := s + sqrt (i);
i := i + 1;
fait;
fin;
Des
déclarations, le traducteur peut conclure que l'affectation
s := 0 est une affectation de la valeur
0 à un nombre réel, alors que
i := 0 est une affectation entière.
De même, l'addition dans
s := s + sqrt (i)
est une addition entre des nombres réels, alors que l'addition dans
i := i + 1 est une
addition entre des nombres entiers.
Cette phase d'analyse comporte une part importante de
contrôle, puisque le traducteur peut constater des éléments
incompatibles ou ambigus, ou des actions qui n'ont pas de sens. Les erreurs qui
peuvent être découvertes à cette étape, sont par
exemple l'absence de déclaration ou des déclarations
incompatibles, des identificateurs déclarés, mais
inutilisés, des expressions sans signification (ajouter des réels
et des chaînes de caractères, par exemple), etc...
Bien des contraintes que l'on trouve dans les langages de
programmation modernes, et qui paraissent superflues a priori, n'ont en fait
pour but que de garantir au programmeur que la sémantique déduite
par le traducteur de son programme ne présente aucune
ambiguïté. Si ce n'était pas le cas, cela impliquerait que le
traducteur pourrait prendre une sémantique différente de celle
voulue par le programmeur, et que deux traducteurs différents du
même langage pourraient déduire des sémantiques
différentes.
4.4. La génération et l'optimisation de code
La phase de génération de code est la phase de
traduction proprement dite. Elle n'est entreprise que si aucune erreur n'a
été trouvée. Elle consiste à construire un programme
équivalent à la sémantique obtenue dans la phase
précédente, dans un nouveau langage, et donc en particulier dans
le langage de la machine lui-même. Le plus souvent, l'analyse
sémantique produit une structure particulière qui regroupe
l'ensemble des informations obtenues sur le programme. La
génération exploite simplement cette structure pour produire le
code.
La notion d'optimisation est plus intéressante.
L'écriture de programmes dans un langage évolué permet de
s'abstraire des particularités de la machine, mais a pour
conséquence de ne pas toujours donner un programme traduit aussi efficace
que si l'on avait directement programmé dans le langage d'assemblage.
L'optimisation de code a pour but de compenser cet inconvénient. On peut
dire que la qualité d'un compilateur peut se mesurer par
l'efficacité du code machine produit, et repose en grande partie sur les
techniques d'optimisation qui sont mises en jeu. Il n'est pas question d'en
expliquer ici le fonctionnement, mais de donner quelques indications sur ses
possibilités.
- Tout d'abord, le compilateur peut
déterminer les expressions constantes, c'est-à-dire dont le
résultat peut être connu à la compilation, et propager cette
valeur le plus possible dans le programme.
- Il est
facile également d'éliminer le code inaccessible. Le but essentiel
est de diminuer l'espace mémoire du programme résultat. C'est une
solution élégante au problème de la compilation
conditionnelle. Par exemple, si le compilateur constate qu'une condition
d'une instruction conditionnelle est toujours fausse, il peut éliminer
toutes les instructions qui devraient être exécutées dans le
cas où la condition est vraie.
- Il peut
déplacer des parties de code pour faire sortir d'une boucle des
instructions qui produiront le même résultat à chaque pas de
la boucle.
- Il peut éliminer les calculs
liés aux variables d'induction de boucle, pour les remplacer par d'autres
plus essentiels. Par exemple, la progression d'un indice dans un tableau peut
être remplacée par la progression d'une adresse sur les
emplacements du tableau.
Il ne s'agit pas
d'améliorer un programme mal écrit, mais d'atténuer
certaines inefficacités dûes à l'écriture de
programmes dans un langage évolué.
4.5. La traduction croisée
Un traducteur est un programme exécutable particulier
qui prend pour donnée un module source, et fournit comme résultat
un module objet. En tant que programme exécutable, il s'exécute
sur une machine particulière qui comprend le langage dans lequel il est
écrit. Si cette machine est bien souvent la même que celle à
laquelle sont destinés les modules objets qu'il produit, ce n'est pas une
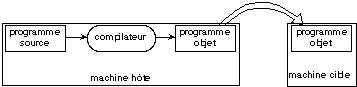
obligation. Lorsque les deux machines sont différentes, on parle de
traduction croisée. Le traducteur s'exécute alors sur une
machine hôte, et produit des modules objets pour une machine
cible (figure 4.2).
Fig. 4.2. Traduction
croisée.
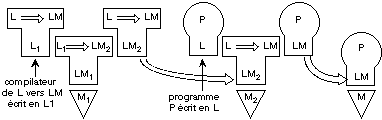
Plus généralement, le traducteur est
lui-même écrit dans un langage d'assemblage, ou plus souvent dans
un langage évolué L1 ; il accepte en entrée un
module source écrit dans un langage L qu'il traduit en un module objet
écrit en un langage LM. Par le biais d'un traducteur de L1
vers LM2 s'exécutant sur une machine M1, on obtient
un traducteur de L vers LM écrit en LM2, qui peut
s'exécuter sur une machine M2 si le langage de M2
est LM2. Ce traducteur de L vers LM permettra de traduire sur la
machine M2 les programmes écrits en L en des programmes
écrits en LM qui pourront s'exécuter sur les machines M dont le
langage est LM (figure 4.3).
Fig. 4.3. Représentation
schématique de la traduction croisée.
Le schéma de traduction croisée a un cas
particulier représenté par la figure 4.4. Le traducteur C du
langage L vers le langage LM est écrit dans le langage L lui-même.
On emprunte pendant quelque temps un traducteur C1 de L vers LM écrit en
LM. Il est donc capable de traduire C en un traducteur équivalent C',
écrit en LM. Les performances d'exécution de C' sont directement
liées aux performances du traducteur C1. On peut alors utiliser notre
traducteur C' de L en LM écrit en LM sur la machine M pour de nouveau
traduire C en C". Cette fois, les performances d'exécutions de C" sont
celles que nous avons définies dans notre traducteur C de L en LM, qui
s'est donc autocompilé. En général C" est différent
de C', car ils sont tous deux produits par deux traducteurs différents.
Par contre, si on recommence l'opération en traduisant C par C", on
réobtiendra C". Ceci est parfois utilisé à des fins de
contrôle de bon fonctionnement de la suite des
opérations.
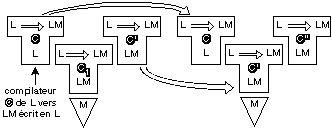
Fig. 4.4. Représentation
schématique de l'autocompilation.
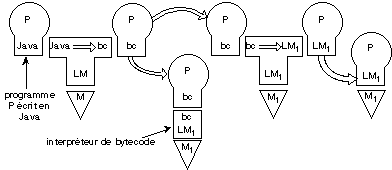
Nous avons vu que, dans le cas du langage Java, il est
habituel de combiner une phase de traduction de Java en bytecode et une
interprétation du bytecode par une machine virtuel (simulation par
logiciel de la machine). Ainsi tout programme java peut être traduit en
bytecode sur une machine M, envoyé sur n'importe quelle autre machine M1
pour être exécuté pourvu que celle-ci dispose d'un
interpréteur de bytecode. Cependant, pour pallier le manque de
performance inhérent à l'interprétation, la machine
réceptrice peut également traduire le bytecode en son langage
propre et le résultat être exécuté directement sur
M1. Un tel traducteur est encore appelé just in time compiler
(figure 4.5).
Fig. 4.5. Représentation
schématique du système Java.
4.6 Conclusion
+ L'assembleur est un programme
qui traduit un programme écrit en langage d'assemblage, à base de
codes mnémoniques d'opérations d'une machine dans le langage
binaire de cette machine.
+ L'interpréteur est un
programme qui simule une machine qui comprend un langage
évolué.
+ Le compilateur est un
programme qui traduit un programme écrit dans un langage
évolué dans le langage binaire d'une machine, pour que celle-ci
puisse l'exécuter.
+ L'analyse lexicale consiste
à reconnaître dans une chaîne de caractères la suite
des symboles du langage et à en donner une codification
interne.
+ L'analyse syntaxique consiste
à retrouver la structure syntaxique d'une suite de symboles et à
vérifier sa conformité aux règles du langage.
+ L'analyse sémantique
consiste à trouver une signification, indépendante de tout
langage, aux actions définies par le programme.
+ L'optimisation a pour but
d'atténuer certaines inefficacités dûes à
l'écriture en langage évolué.
+ La génération
de code consiste à traduire la sémantique du programme dans le
langage binaire de la machine.
+ La traduction croisée
consiste à utiliser un traducteur qui s'exécute sur une machine
hôte pour produire un résultat qui s'exécute sur une machine
cible différente.
+ En fait, tout programme
qui interprète des données venant d'un utilisateur devrait
comporter les phases d'analyse lexicale, syntaxique et
sémantique.
[1] Notons que c'est l'absence
d'une telle définition correcte pour le langage FORTRAN qui a
été la cause de l'une des erreurs de programmation les plus
coûteuses pour la NASA. Un “point” ayant été
tapé à la place de la “virgule”, le compilateur a
traduit l'instruction de boucle "DO 50 I = 1 . 5" par une simple affectation de
la valeur 1.5 à la variable "DO50I". La sonde de Venus est passée
à 500 000 km de sa cible.